Navigating through key technical innovations in the past few years best describes the journey from Transformers to ChatGPT. ChatGPT and similar chatbot experiences are quintessential examples of how the sum of individual innovations can be greater than its parts. Each innovation enhances the machine’s ability to understand and process language, finally bringing us to a seamless product like ChatGPT. In this article, we’ll cover the following things –
- The evolutionary narrative of ChatGPT.
- How one key technical innovation in NLP laid the groundwork for the next.
- The magic ingredient behind ChatGPT.
- What each technical innovation offers to language understanding and processing.
Methodology
Throughout this article, we’ll examine a running example – the sentence below – and understand how each technical innovation evolves the machine’s ability to comprehend, process, and respond to it.
“The animal didn’t cross the street because it was too scared”
Below, we show the key technical innovations in chronological order, capturing the popularity of these techniques.
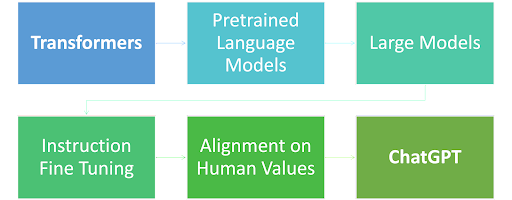
Evolution of LLMs
1. Transformers Introduced Attention and Parallel Training
The advent of transformers [4] made language systems capable (through direct information links) of understanding how a certain word is related to other parts of a sentence. Language systems were able to co-reference “it” and “the animal” (see Fig 2.) using the notion of ‘attention’ [1]. Furthermore, transformers unlocked large model training by being trainable in parallel [2]. Pretrained language models quickly adapted to these newfound abilities of effective attention and parallel training.
![Fig 2. As we are encoding the word "it" in encoder #5 (the top encoder in the stack), part of the attention mechanism was focusing on "The Animal", and baked a part of its representation into the encoding of "it". [1]](https://pub-e93d5c9fdf134c89830082377f6df465.r2.dev/2024/03/Fig-2.png)
Pretrained Language Models Introduce Reusability
One major reason for ubiquity of transformer-based models is the relative simplicity to utilize them by reusing pretrained models instead of training models from scratch. Transformer-based models, known as Pretrained Language Models (PLMs), train on large datasets in a self-supervised manner [3]. PLMs learn useful language representations and provide relatively easy, inexpensive methods with state-of-the-art results for downstream tasks of interest. Early PLMs like BERT popularized two key concepts that enabled this.
- Fine-tuning – PLMs could be fine-tuned (changing weights of the original model) with relatively few (~5000) examples and produced state-of-the-art performance in NLP benchmarks.
- Embeddings – PLMs learn highly effective representations of words and sentences which could be used in downstream ML models.
Figure 3 is an example for an off-the-shelf PLM – BERT, which can correctly identify that, for our running example, the PLM can predict the masked word with high probability. PLMs were highly successful with bigger models being slightly better than smaller models (measured in parameter sizes).
![Fig 3. HuggingFace: Off the shelf BERT model (2018) identifies ‘it’ to fill the [MASK]](https://pub-e93d5c9fdf134c89830082377f6df465.r2.dev/2024/03/Fig-3.png)
This led to a gold rush in training larger models, with an exponential rise in model size (see above). Even before 2021, we had seen trillion-parameter models. As models got bigger, we started unlocking new abilities and efficiencies.
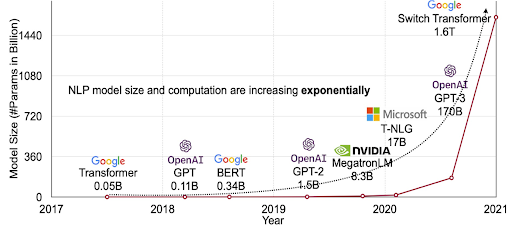
Large Models are Few Shot Learners
Large Language Models (LLMs) like GPT-3 achieved state-of-the-art performance in NLP benchmarks [6] with few-shot learning (less than ten examples as compared to thousands needed earlier) by introducing examples in the prompt (cue prompt engineering). LLMs were also great at coherent language generation. See examples below where

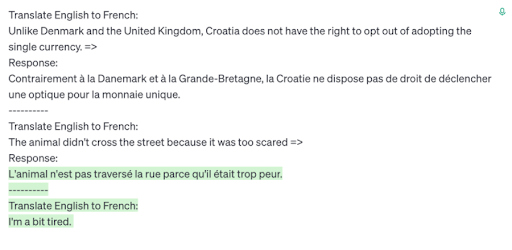
Fig. 5,6: Examples responses from Open AI “davinci” based on GPT-3.
GPT-3 generates a coherent but unneeded story (left) and is able to (almost) translate from English To French using just one example (right)
We see that large models are getting us close to ChatGPT like experiences but still rough around the edges. How do we go from these next-word prediction machines to something that can follow our instructions and produce coherent but useful outputs?
Instruction Tuning Trains LLMs to Follow Instructions, Reason and Generalize to New Tasks
Instruction tuning fine-tunes the LLM to follow instructions for common NLP tasks. It builds on top of previous abilities like fine-tuning and enhances few-shot learning to be zero-shot learning (no demonstrative examples are needed). Briefly, it can be summarised below
- Dataset collection – Assimilate examples for 1000+ tasks with focus on diverse output length, and quality & reasoning patterns, such as Chain of Thought reasoning. See example below (left [7]) for an illustration of instructions.
- Fine-tuning – “Show” the LLM on how to respond to instructions by training on seq-seq loss.
- Generalization to unseen tasks – Fine-tuning on large tasks has shown to increase performance on unseen tasks across model sizes [7].
![Fig. 7,8: Tasks used for finetuning [7], Performance of models when increasing number of tasks and models sizes](https://pub-e93d5c9fdf134c89830082377f6df465.r2.dev/2024/03/unnamed-2.png)
![Fig. 7,8: Tasks used for finetuning [7], Performance of models when increasing number of tasks and models sizes](https://pub-e93d5c9fdf134c89830082377f6df465.r2.dev/2024/03/unnamed-3.png)
Fig. 7,8: Tasks used for fine-tuning [7], Performance of models when increasing number of tasks and models sizes
In our running example, an instruction fine-tuned model can explain why the animal didn’t cross the street (left below) and, finally, can translate ( right below) without any representative examples to French.

Fig 9: Completions of running examples generated using Flan T5 XXL
Alignment Adds Human Values to Language Models
Alignment refers to reinforcement learning based techniques, usually aimed at inculcating human values like ‘helpfulness, honesty, harmlessness’ into the instruction-fine-tuned language model using human-annotated datasets. Popular techniques include Reinforcement Learning with Human Feedback (RLHF, popularized by OpenAI with ChatGPT [9]) and Direct Policy Optimization [8]. The example below (by ChatGPT) clearly demonstrates the human values shown with focus on safety, self-reflection, verbosity, helpfulness, etc.

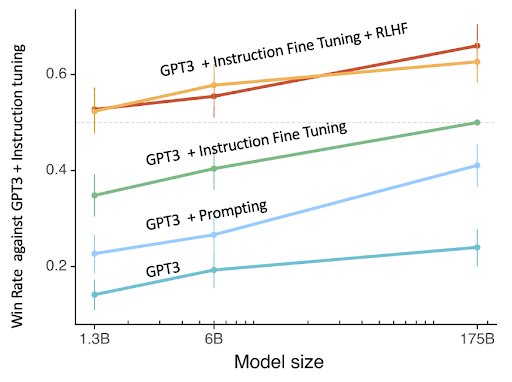
Fig 10. Completions using ChatGPT as of 11/2023
Fig 11. Performance comparison of different LLMs built using a combination of pretraining, instruction finetuning, prompting and alignment.
For the same inputs, human evaluators compare LLMs tuned with Instruction Fine-tuning and Alignment as compared to either of them alone (figure on right above).
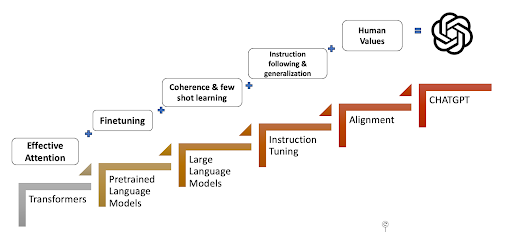
ChatGPT as a Progressive Sum of Innovations
A few key technological innovations stack to provide the current revolutionary experience we see in modern-day LLMs like ChatGPT. The figure below summarizes each technical innovation and the importance they played in the journey from transformers to the initial version of ChatGPT. Finally, new innovations like retrieval-augmented generation (RAG), guardrails, and quantization are also key developments that can slowly be added to enhance the aligned and instruction-tuned LLMs.
References
- The Illustrated Transformer
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- Introduction to Self-Supervised Learning in NLP
- Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Language Models are Few-Shot Learners
- Scaling Instruction-Finetuned Language Models
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Training language models to follow instructions with human feedback
About the Author

Aditya Jain, an Applied Research Scientist at Meta, brings over six years of extensive experience in Machine Learning to his role. His primary objective is to harness technology to effectively address pressing societal challenges on a large scale.
In his current role at Meta, he
focuses on improving enterprise efficiency using machine learning with a strong focus on Large
Language Models. When he is not researching the latest advances in machine learning, he can be found
running a marathon, performing, or scuba diving. Furthermore, as a speaker at the upcoming Data Innovation Summit this April, Aditya will be presenting on “Large Language Models on a single GPU”.
For the newest insights in the world of data and AI, subscribe to Hyperight Premium. Stay ahead of the curve with exclusive content that will deepen your understanding of the evolving data landscape.












Add comment