
Digital twins are virtual representations of real-life manufacturing assets. But they are not only models of the physical objects; they serve as a bridge and co-creation between data scientists and engineers. Most importantly, they enable meeting the goals of digital transformation by monitoring performance, effectiveness, and quality of the manufacturer’s assets and machinery by capturing real-time sensor data from the objects. But, as the title suggests, in this article, we are going to explore the concept of probabilistic digital twins.
What are probabilistic digital twins (and how they differ from digital twins)
The foremost goal of predictive and prescriptive maintenance in the oil and gas industry is the safety of the people and the environment, for which purpose the risk of the operations needs to be captured and calculated.
However, what digital twins fail to capture is the risk of assets and the environment to prevent failure. And in order to calculate risk, we need to capture the uncertainty of the assets. This need for capturing and calculating the uncertainty in the oil & gas industry created the probabilistic digital twins – an innovative asset integrity maintenance approach that Arvind Keprate, Senior Engineer at DNV GL revealed at the Maintenance Analytics Summit.

Probabilistic digital twins present a marriage between digital twins and dynamic risk models, elaborates Arvind.
From his mechanical engineering perspective, Arvind describes the digital twins as replications of the physical assets in the virtual world. Another important aspect to this physical-virtual world relation is the digital thread which is the link between the sensors on the physical asset and the point of capturing the data in the virtual environment. All the forces and laws that are applied to the physical asset are virtually simulated to the virtual asset.
Nevertheless, the concept of digital twins is nothing new. In fact, Arvind states that the term was coined back in 2002, and since then digital twins have gone through a great revolution.
In a previous article, we presented Diego Galar’s presentation of the different generations of digital twins, from digital twins 1.0, digital twins 2.0, digital twins 2.1, and the most sophisticated generation of digital twins 3.0 or hybrid models.
Avrind, in turn, gives an overview of the past, present and future of digital twin maturity, where the past is status-only digital twins very similar to condition-based monitoring. The present state is operational and simulational digital twins, i.e. the predictive and prescriptive analytics we are heading towards today. The future state is cognitive digital twins that embody previous traits and can give autonomous prescriptions based on past actions, correlations and outcomes.

Oil and gas pipelines and digital twins
To give us a context for the conditions the oil and gas industry is working in, Arvind gives us several facts about the Norwegian underwater pipeline network. As he explains, the Norwegian pipelines are the longest in the world, with an accumulative length of 8000 km all the way from Oslo to Bangkok. Norway caters for 25% of EU energy consumption, and if production stops, it costs 60 million US$ per day.
So we can conclude that oil & gas pipelines are a truly valuable asset for the entire world, but especially for Norway and their integrity needs to be maintained.
But how does one perform asset integrity maintenance on a several hundred kilometres long pipeline? Instead of putting sensors at every kilometre, there is a much more efficient way by running a sensor through the 500-kilometre long pipeline. This moving sensor is called a PIG – Pipeline Inspection Gauge, which consists of sealing disks, rollers, sensors and magnets. When the PIG runs through a pipeline, it caches data from the pipes.
However, there are several challenges with using a PIG to capture sensor data:
- No continuous digital thread, but at an intermittent level since the PIG is in motion. And as we know, a continuous digital thread is necessary for a digital twin. This poses the question of how long should operators run it in a pipeline.
- Sensor location is also a problem. As Arvind explains, the biggest threats for pipelines is corrosion, which is a local phenomenon. So we can’t predict that corrosion levels will be the same for all kilometre intervals.
- The cost of running an intelligent PIG is approximately 1 million USD, and if it’s run more frequently, it amesses a substantial amount of cost.
- There is a compromise between safety and cost, which means choosing whether to run it less frequently to save money, or run it more frequently to increase safety.

Probabilistic digital twins as a solution
Faced with the above difficulties with digital twins of pipelines, DNV GL developed their own pilot solution based on probabilistic digital twins. As Arvind explained earlier, probabilistic digital twins are a confluence of digital twins, (covering physical asset, virtual twin and digital thread) and dynamic risk models which allow them to capture uncertainty and reflect risk.
The components of probabilistic digital twins are:
- Failure and degradation models
- Logic and relational models
- Surrogate models
- Supports operational decisions
The most crucial components, according to Arvind, are the logic and relational models. One example of these models is probabilistic graphical models such as the Bayesian Network and the Markov Network.

Bayesian networks & Bayesian thinking
Bayesian networks help to capture the logic that the human experts have, besides the sensor data. They rely on the concept of Bayesian thinking.
Arvind explains Bayesian thinking as a simple phenomenon by which we make decisions every day. We have some prior belief, we perform a test or experiment, and we end up with a posterior belief. But when we are presented with new evidence/information, our prior belief changes. With Bayesian thinking, we make our decisions conditionally – based on the most recent evidence and events.
Bayesian networks, in turn, are a simple way of representing Bayesian thinking with the help of directed, acyclic graphs (DAGs). They consist of directed nodes (parent node and child nodes) structured hierarchically.
The directed arrows connecting the graphs have the probability dependencies between them represented in condition probabilities tables. The Bayesian networks can even be trained with the help of ML algorithms, states Arvind. And that is what they have done in their pilot project with probabilistic digital twins.
The Bayesian networks presenting animals below offer a simple explanation of how they work:
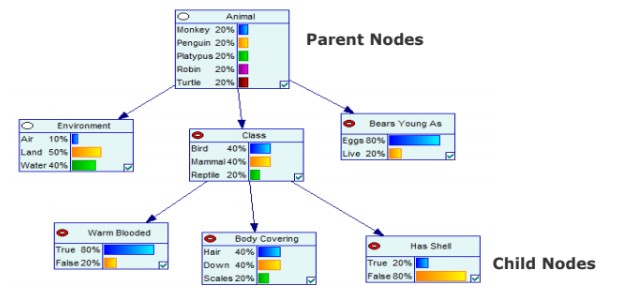
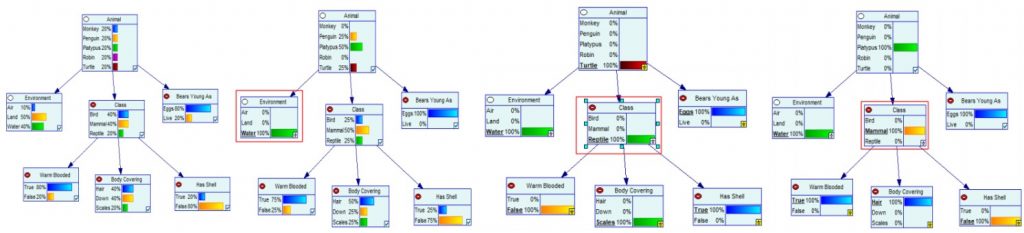
As the evidence is changing along the way, so do the posterior distributions. We start with uncertainty, and as we get more information, we narrow down the probabilities to the final outcomes.
The reason why Bayesian networks are used to create probabilistic digital twins is that:
- Graphical representation: Because of the graphical structure of Bayesian networks, people can understand the problem in an easy and simple way.
- Learning: They can combine human learning (exert belief) & machine learning (data).
- Inference/reasoning: The process of reasoning and computing in order to reach posterior distribution. There are two types: causal reasoning and evidential reasoning.

How Bayesian Networks are used for pipeline integrity maintenance
With the help of these two types of reasoning, we can predict when the asset will fail using causal reasoning, and what was the reason for the failure using evidential reasoning.
The same Bayesian network can provide an answer to these two different questions.
The causal reasoning is used to extend the lifetime of the pipelines. While, when the asset has already failed, evidential reasoning is used to find out what caused it to fail.
Final thoughts
Probabilistic digital twins are a confluence created to overcome the shortcomings of digital twins, which don’t reflect the uncertainty, which is important for risk evaluation, and Risk Models used in safety management that often lack real-time capabilities.




