Some years ago, organizations faced the challenge of insufficient computing power, storage capabilities, or data to invest in developing ML and AI models. Today, companies with a lot of data face a challenge on how to build, train, deploy, and scale AI and ML models, applications, products or projects in production, and all at a low cost.
Since DevOps (a portmanteau of “development” and “operations”) reached its limits in addressing the challenge, a new paradigm was introduced – MLOps (machine learning operations). According to Tanu Chellam, a VP product at Seldon, “MLOps are the interaction and interconnectedness of software engineering, machine learning and developer operations. When these three roles come together, that shapes ML processes and framework is really about.”
In other words, MLOps is a collection of tools and principles that support the whole ML project life cycle: scoping (defining projects), data (labeling and organizing data), modelling (training the model and performing analysis) and deployment (deploying the model in production and monitoring the system). It makes the whole process more transparent and efficient.
This being said, where are the MLOps at the Gartner hype cycle in 2022? According to Oswaldo Gomez, an IT Expert MLOps at Roche, there is agreement among the community, that the MLOps is beyond the peak of inflated expectations and on the slope of enlightenment where many good things are maturing and coming. So, why is operationalisation of ML products hard, and why is it slow to move models from research and development (R&D) to production?
Operationalizing and Moving from Research and Development to Production
MLOps processes are for machine learning engineers and data scientists what DevOps is for software engineers. When an organization starts with ML, it starts with experimentation. At this stage, data is collected and cleaned as much as possible. The better the quality of data the better the quality of models, and better and more accurate predictions the models are able to make. The next step is configuration and figuring out which features the orgaisation wants to track. “After this, the hard part comes.”, says Tanu Chellam and adds that it can take months if there are many people and many steps associated with the process (model source control, data retention policies, model oachaking, model validation and model deployment).
“As you constantly monitor the data, and the models or data are changing (new source of data or the configuration is changed, so the model is not predicting accurately), it is time to look at the data all over again, and make sure it is sanitized and look what needs to be reconfigured for improved accuracy. Monitoring is important to look at the data drift. At this stage you go back to the experimentation phase in order to make some of these changes. This is why it is never ending and continuously managing ML operations and pipelines. When someone is evaluating a MLOps platform, it is important to consider all steps and factors. Incorporating a multitude of automated processes within the MLOps system and framework will help you streamline the time required to experiment or move to production or retrain. All this is impacting R&D, either it is costly to do these steps manually or it is preventing (organizations) from achieving better revenue.”, explains Chellam.
For many organizations, operationalization of the MLOps is hard because of all the technical challenges and risks that often arise when managing several ML models. When an organization is in the experimentation phase and managing just one or two models is not that hard to manage it manually without systems in place. But once the organization has more models, a system or management process is needed to understand what’s happening with the models and data. Automation of the processes is helpful along the journey.
Why operationalization of the MLOps is important for the organizations? There are three key reasons:
- Degraded models performance lower Return of Investment (ROI). As data and inputs change the models will perform more or less accurately than before. If the data and model performance is not monitored, it associates with lower ROI since the model is less accurate and predicting and forecasting will impact the decision outcomes and will impact the end user along the way.
- Difficult to scale systems cause slow workflows between data science and DevOps teams. Any system or process will help elevate some of the problems and with better collaboration, organizations can have better outcomes.
- Lack of oversights leave business at risk of fines, reputational damage and financial loss. Organizations would be better to mitigate these risks early on. These risks may arise if the data and the model performance are not constantly monitored.
Challenges and Best Practices Through Industries
Finance sector – The financial sector is “blessed” with a lot of different types of data: tax, loans, demographic, bank account transactions etc. But there are also many challenges to this data since the type and distribution of this data changes a lot. This can be caused by changes to the financial market or the external data sources used. In this case, MLOps is very important and addresses the pitfalls of machine learning on this type of data, which also includes data centric and responsible AI. The challenges of Noitso, a Danish company for optimising credit ratings and automating big data in the financial industry, was also in the development phase, when the ML model was communicated between the data scientist and software engineer. The solution for this problem was building containerized machine learning using docker, Kubernetes and Seldon. Furthermore, there was a need to monitor and explain machine learning.
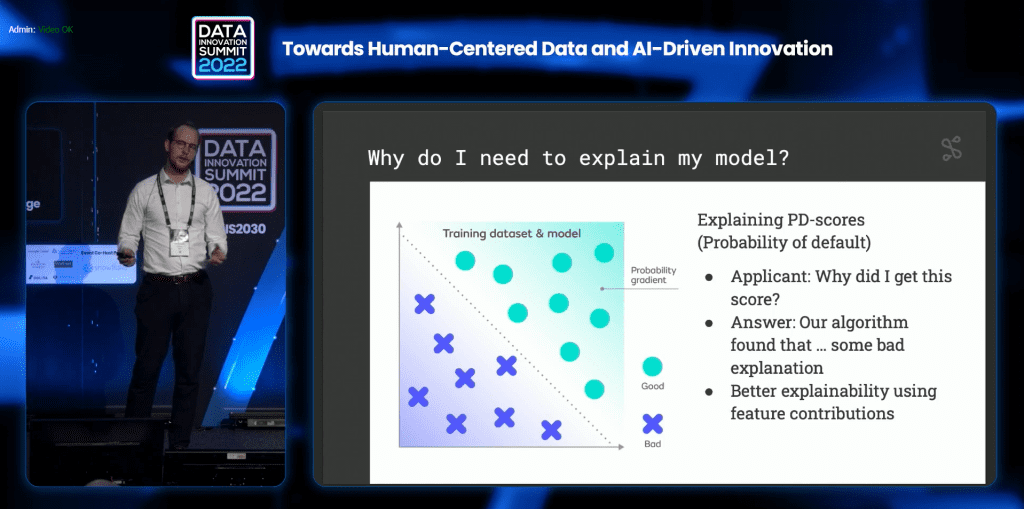
“Monitoring can be looking for data drift where the distribution of the dataset is compared with a batch of the incoming data. If there is a significant difference, it suggests that the model is making predictions on data that diverges significantly from its training data. Monitoring is also looking for outliers in the data which work in a similar way. Instead of monitoring incoming data as a whole, we focus on monitoring individual data points. This approach allows us to not only monitor but also gain insights into how the ML model interacts with the data. There are many reasons for explanation. It is because of compliance with regulations, where there is a need for documentation of what ML showed or did right. It is also to show how the system affects the users, so it is about responsible AI, too. The other reason is about data literacy and educating the organization on what ML is and how it works. This is also crucial to be successful in a ML project. When explaining the model, organizations should focus not just on explaining the algorithm but the data that the algorithm used or what we call using feature contribution methods.”, says Thor Larsen, Data Scientist at Noitso.
Health sector – Roche, the Swiss and worldwide healthcare company, has several MLOps teams (that have ownership of the operational content and the technical stack). This structure has the potential to accelerate the drug discovery process by enabling pathologists and scientists to make predictions using AI and ML which is necessary in order to meet their ambitious goals to deliver double the benefit to patients at half the cost to society.
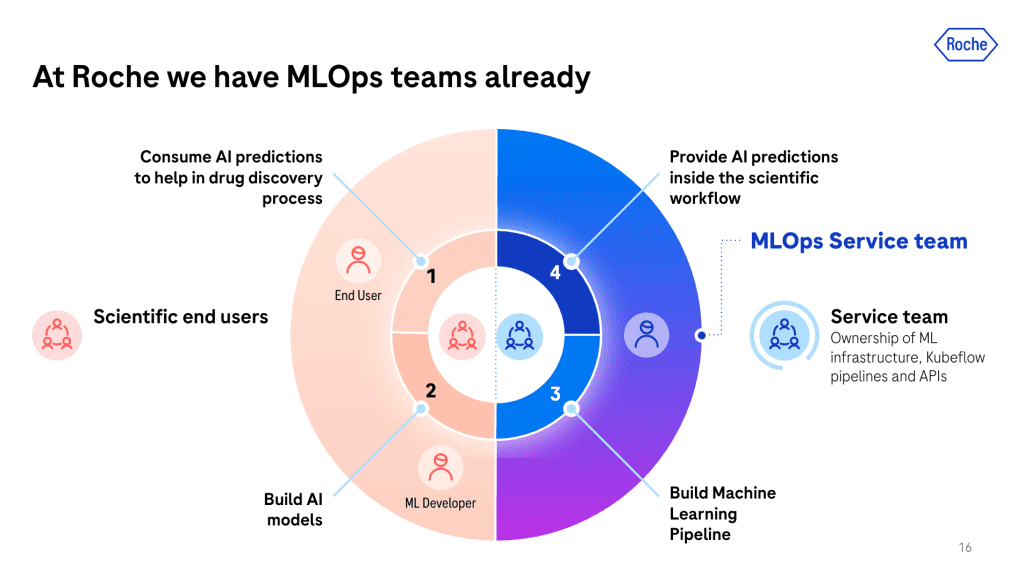
“We are finding innovative ways to deliver value to society. We have an MLOps team that works to make the platform highly available, scalable and maintainable while simultaneously align with the data scientists to design and build together our automatic ML pipelines. Then, we embed the AI predictions into their scientific workflows. However, we cannot stop here since we have to retrain the models upon receiving new data or changing the AI models”. explains Oswaldo Gomez.
Insurance – How to bring MLOps to the industry that is conservative and resistant to change, and how to scale and bring value out of it? One example is the Direct Line Group, the largest British insurance company. Over the course of 37 years of existence, the company accumulated enormous data and created a rich data environment.
“Data was on different and many systems to which data scientists did not have or had limited access to. And if they got the data, there was nowhere to process it to, or do it on a system not particular to the case. And even if there was ML and a model, there was no means of deploying it and end up in the legacy system. The challenge was how to find pieces that fit together and if you want the value of a data process you need to find an operational model to fit.”, tells Till Buchacher, Chapter Lead (Head of Data Science) at Direct Line Group.
How does the company fix that? By creating a single place/platform to cater the entire DS/ML development chain (from exploration to deployment, with model deployment and management, strong governance and security, and openness of the platform to sourced technology), building around proven MLOps model and by enabling people to choose tools and resources.
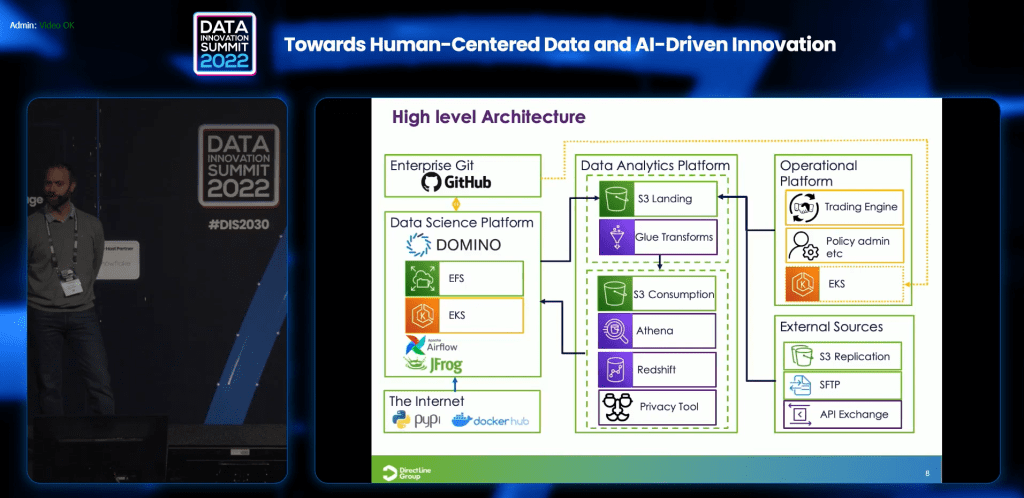
There were hiccups, but we ended up with really nice models that are taking us in the direction where we want to go. The moral of the story with the investment you are making is you need to be clear what you want to achieve, something specific or something general. That depends on who your target audience is, and what you get out of it. We made a decision at the start that we wanted something focused on data science only and with that came all decisions when we started to draw all of our processes. So we made the decision that we want a high code environment for data only, built around clear MLOps processes, we wanted everything to be self-served rather than restricting people around monitoring and wanted to abstract all of the bits that data scientists don’t want to deal with.”, adds Till Buchache.
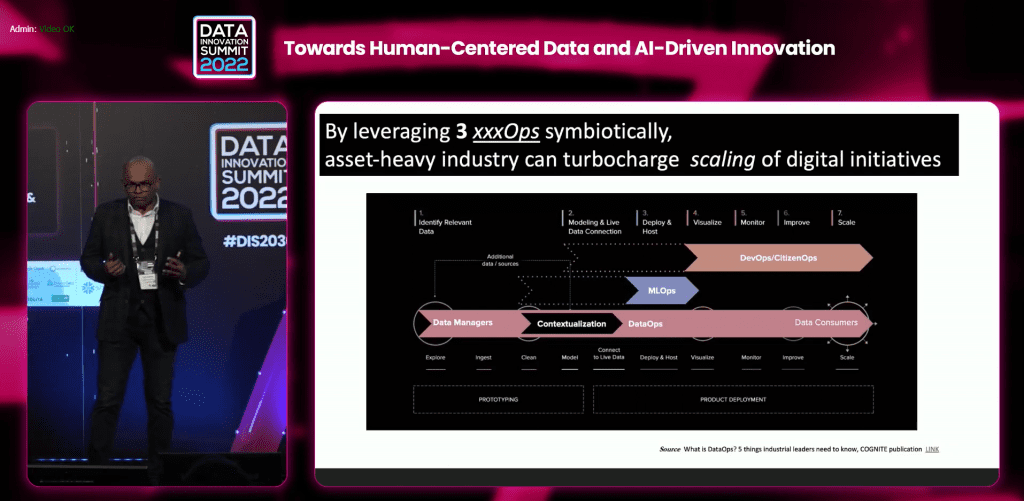
Heavy asset industries – Scalability in heavy industry is important. These industries are facing trends and three of them, according to Dr. Abul Fahimuddin, former Digital Program Manager at Equinor, are competitive advantage has transferred from machines to data/code, empowerment of business data analysts over centralized IT, and proliferation of application software development.
“This is where the problem starts because there are many companies running successful Proof of Concept (POC) but few are going to production and even less will be productionized and maintained over a long time. We need to build DataOps foundations at the same time, have control of MLOps and simultaneously empower DevOps. These three have to be simultaneous otherwise a lot of the potential may be lost.”, says Dr. Abul Fahimuddin.
At the 7th edition of the Data Innovation Summit, he explained this through a data innovation project from the oils and gas industry.
“We started our journey well, we partnered with the best player at the marketplace, did POC, went to pilot, did limited scaling, we put a team around it to maintain the models, value started to flow, there was some good engagement around the data and analytics, but stagnations started to come and we started to see that it was not reaching the promises. The value realization was getting slower, there was a change of technology in the organization, change of priorities and change of people. All dynamic factors that affected us, the potential was not there anymore and the curve started to become flat. The reason is that we didn’t look at three things before we started: no automation of data ingestion, staging, contextualization, productionization considered (DataOps), no strategy around maintaining life cycle of the ML moldes deployment and monitoring (MLOps) and reactive and no proactive to digital competency demand as “pull from business” (citizen DevOps)”, adds Dr. Abul Fahimuddin.
Lessons Learned and Final Words
MLOps provide increased automation, increase the quality of the production model and help organizations focus on governance, eliminating the creation of new processes every time a model is developed. At the same time, MLOps provide integrated tools for developers to build and deploy AI and ML models more efficiently. The industry is trying to figure out how to do MLOps well. But there is no silver bullet, just lessons learnt:
- Invest in reliable, scalable and maintainable systems. Adding data to this takes a new dimension because organizations have to take care of the data quality and model that makes predictions and check if the model is fair and there is no drift.
- Having a team and processes in place. MLOps is complex, and to master everything is even more challenging. Work in teams. There are many people in the MLOps; everyone has different concerts, but everyone must collaborate.
- Having a solid monitoring and maintainable system is essential.
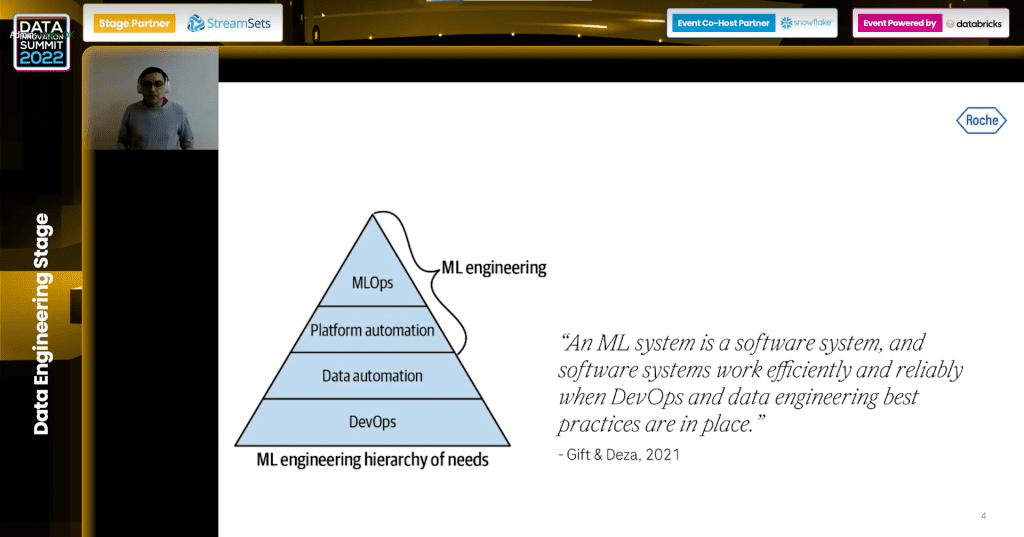
- Start with DevOps and have state-of-the-art DevOps and upwards to the MLOps Maslow pyramid of needs.
The NDSML Summit is the perfect place for key presentations that will share insights from more success stories and lessons learned on how to scale MLOps for increased benefit to the organizations.