
Before delving into the machine learning aspect of email optimization, it is worthwhile to first consider what we would consider a perfect model and explore the realities of what we have to work with. Imagine we have a bunch of email templates ready to send out to our customer base, each one with different goals in mind and each one highly customizable; everything from the header to the colour scheme to the promotional amount offered can be changed on a per customer basis. One possible answer for this ”perfect” model is one that is able to look at a player’s full history of interactions and behaviour, including how they’ve responded to emails in the past, and decide exactly what they need. In other words, a model which is able to learn the relationship between customer features and metadata, email features, and the key performance indicator (KPI) of interest. With this in mind, let’s consider how we might answer the following questions:
• How do we acquire training data when there’s a practical limit on how many emails we can send to customers?
• What machine learning framework works best for personalized email optimization?
• If our customer base is segmented based on different business goals (e.g. churned customers will get emails inviting them to come back, VIPs may get emails about exclusive games), how should the machine learning framework adjust?
Although these questions may appear more technical than business-oriented, we will explore why each of them in turn require important decisions to be made, from both a machine learning and business perspective.
Data Acquisition: The Exploration/Exploitation Balance
For the sake of simplicity, let us consider that we are sending out a brand new email template that has never been sent out before. Our business has years worth of user data, but no information on how our customers will respond to this new template. We’ve already ruled out sending every email to every customer as an unfeasible strategy. Sending out emails in a uniformly random way may be an efficient way to gather data (high on the exploration scale), but we’re likely wasting valuable time sending unwanted emails to customers and perhaps reducing their overall experience. Sending out a few emails over a couple of weeks and then constantly re-sending the ones which performed best (high on the exploitation scale) is a slightly more data-driven strategy, but it is likely under-performing when so few emails have been exposed to the customer base, not to mention that customers like variety in their promotions.
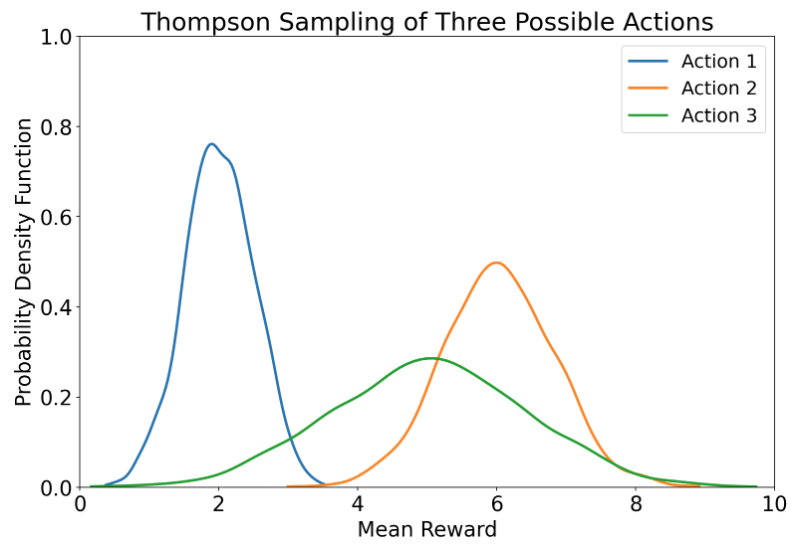
Figure 1: Thompson Sampling is an algorithm capable of choosing from a set of possible actions in a way that balances exploration and exploitation. A posterior distribution over functions in some family f ∈ F is kept track of and updated as new data comes in. The action chosen is the maximum after sampling from the distributions of each function. For example, in a greedy setup, Action 2 will always be chosen as it has the highest mean, but in Thompson Sampling Action 3 also has a chance to be picked given the high variance of its posterior distribution (likely due to it not being chosen much in the past).
As with many things in data science, from learning rates to network depth, a trade-off needs to occur to achieve optimal performance. In this case, we want to explore the range of possible emails a customer wants to see while gradually sending more and more of what they’ve responded to positively, in other words achieving an exploration/exploitation balance. A few algorithms exist for exactly this purpose, and include
• ε-greedy, which chooses the best action 1-ε of the time and selects randomly otherwise
• Upper confidence bound (UCB), where the reward is the sum of the exploitation and a tunable exploration part that drops when the action is sampled more often
• Thompson Sampling, which is explained in Fig. 1. This technique can be done explicitly or implicitly through dropout in the neural network [1]
The choice of sampling algorithm is one of the first decisions to be made when it comes to data acquisition for email optimization, and tuning the exploration/exploitation balance will depend on parameters like how long the email template will be relevant and whether the goals of the company at the time are more KPI-focused or data-driven.
Framework Choice: Reinforcement Learning and Multi-Armed Bandits
Reinforcement learning is a branch of machine learning that is often heard in the context of robots moving around or self-driving cars. Its general idea is that there is an agent looking to maximize its rewards (e.g. getting a passenger from A to B safely) by taking some actions after observing the state it is in a given environment (e.g. stopping at a stop sign). Multi armed bandits (MABs) are a subset of this discipline where we assume that the action taken by the agent does not influence the next state of the environment; an example where this is not the case is the famous cartpole problem, where a robot attempts to balance a thin pole vertically on a cart by sliding back and forth: every choice made to move the cart left or right changes the environment the next choice is made in. By contrast, an MAB may be seen in the context of film or product recommendations, where suggestions to customers won’t fundamentally alter their environment. When it comes to email optimization, these bandits are therefore a natural choice if we imagine sending emails the same way we might suggest films on Netflix or products on Amazon.
Next for definitions comes the term ”per-arm”, which is a way of saying in the context of bandits that the action space (in this case, the emails we will be sending out) will have its own features. Instead of training a bandit to learn individual reward functions for emails 1, 2, · · · , K, which lacks generalization and makes it hard to add possible new emails to the model, having a bandit learn features of the emails (e.g. colour, promotion amounts, type) circumvents these problems while also learning the similarity between different emails. It is therefore a natural choice for a business where emails are highly customizable according to templates, although it does have the disadvantage of forcing a single reward function onto every email, something that may be undesirable if the email templates have very different goals in mind (e.g. retention, acquisition, informational).
One of the last major choices for our framework is how to actually absorb the features and metadata for users and emails and leverage it in a meaningful way that learns the rewards that will be sampled from. Neural networks are a natural choice for this, due to their proven learning capabilities and easy tunability, with hyperparameters like the number of neurons or the learning rate or the depth of the network changeable according to the number and variety of features in the user and action spaces. One choice of infrastructure is a common tower network, as shown in Fig. 2, where both the user and email features are passed through deep neural networks before the output of each is passed to a third network that learns the reward. Deterministic rules can be applied at this stage to limit the action space for certain groups of customers or to ensure a certain amount of variety.
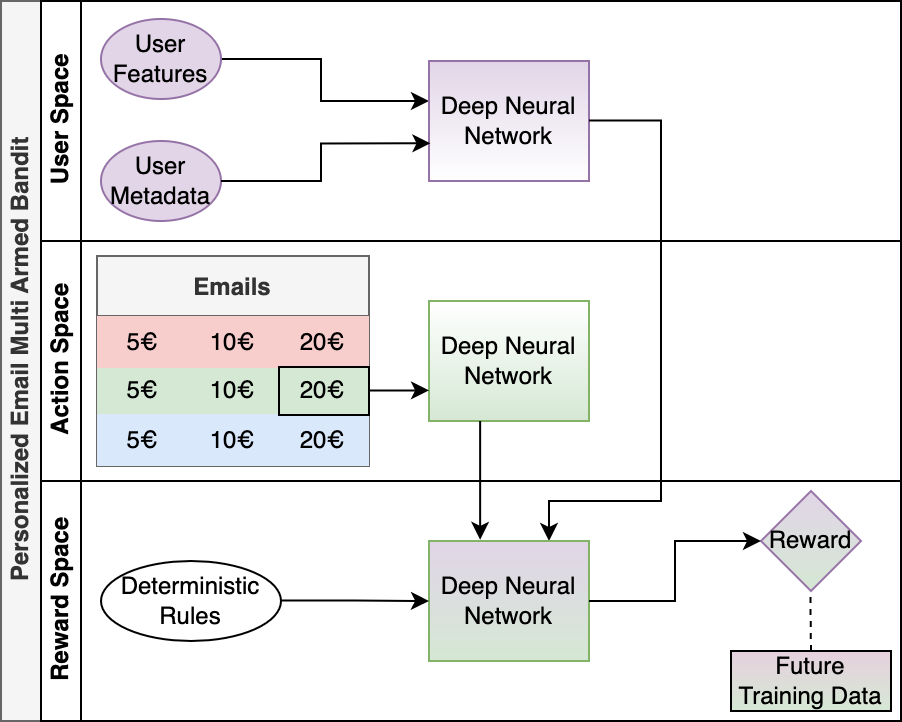
Figure 2: An example implementation of a per-arm multi armed bandit used for personalized email sendouts, utilizing a common tower network scheme. User features and user metadata are passed through a DNN, while the features for each given email (here, a green email offering 20€ is highlighted) are passed through another. A final DNN outputs rewards for selected combinations of users and actions (based on deterministic rules, for example), and a sampling scheme decides on the final rewards, namely the emails sent to the users. How users respond to these emails will define this additional segment of training data.
Customer Segmentation: Another Trade-off
The final question we’ll consider is that of dealing with customer segmentation, namely the bucketing of users according to the KPI we’re seeking to generate from them, from a machine learning standpoint. If the business decides ahead of time that only certain segments of customers should receive certain types of emails, this can be beneficial from a machine learning standpoint if the clustering is done properly. If we settle on a ”per-arm” bandit for email optimization, so that the same reward is trained for all emails for a given user segment, it may be best to have several instances of the bandit for each segment of customers with a different KPI the business seeks to maximize (e.g. retention for new customers, engagement for seasoned ones).
However, the major caveat here is that for all but the very largest businesses, the amount of emails one can gather data from may be quite limited, and segmenting this data across many instances of an MAB may sacrifice the company’s ability to use its data efficiently. This can be mitigated to some extent by having similar features across the multiple instances and treating their data as historical data [2], but ultimately a trade-off exists between how much data you want available for training and how specific the email reward functions need to be.
Conclusion
While a full exploration of the tools and tricks available in the realm of email optimization on the user level would take up multiple textbooks, presented here are some of the main questions that may come to the fore as a business decides the how and why of doing a machine learning approach. Clever sampling techniques are available to achieve the desired exploration/exploitation balance of new training data, reinforcement learning tools that utilize user and email information in a scalable way are able to learn the desired user-email-reward relationship, and choices about how the model deals with customer segmentation all prove valuable in the design and development of email optimization schemes for any business looking to enter the space.
References:
[1] Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning, Gal, Yarin and Ghahramani, Zoubin, arXiv, 2015, https://arxiv.org/abs/1506.02142
[2] Multi-armed bandit problems with history, Shivaswamy, Pannagadatta and Joachims, Thorsten, Artificial Intelligence and Statistics 1046–1054, 2012
About the Author

Keenan Lyon works in the Data Science Team at LeoVegas Group in Stockholm, Sweden. Before joining, he completed his PhD in Applied Mathematics at the University of Waterloo and a Postdoctoral Fellowship at Uppsala University. In his current role he is focussed on solving business-centric problems using deep neural networks, reinforcement learning, and other advanced machine learning tools. Keenan will present at the 2022 edition of the NDSML Summit.
Featured image: Solen Feyissa on Unsplash
The views and opinions expressed by the author do not necessarily state or reflect the views or positions of Hyperight.com or any entities they represent.











