
It has been said before by many of the experts we’ve had at our events that the financial sector is probably among the first early adopters to deploy machine learning (ML) to improve performance and enhance the quality of services and products. But many experts also emphasize the difference in how much public and private markets use ML and deep learning. The conclusion is that public markets are more data-driven and use an algorithmic approach. In contrast, private markets still have difficulty gathering and sharing data due to confidentiality. This has been an obstacle for applying ML and deep learning since the models require a large amount of annotated data.
However, technological innovations affect the private markets. Because of digitization, large amounts of data on private companies are publicly accessible. So, they also try to be data-driven and use the benefits of automation, objectiveness, consistency and adaptability. Many processes would benefit from applying deep learning. One, for example, is competitor mapping.
This article presents one solution that proposes a way to overcome the challenges that private markets face when applying ML and deep learning. The proposed solution is PAUSE – Positive and Annealed Unlabeled Sentence Embedding. PAUSE was proposed by Motherbrain, a digital platform that leverages Big Data and Machine Learning to make EQT truly data-driven in finding the best tech start-ups to invest in. The academic paper where Motherbrain elaborates PAUSE was accepted for publication by the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), one of the best Natural Language Processing (NLP) academic conferences in the world of AI.
During the Data Innovation Summit 2022, Lele Cao, Senior Data Scientist at EQT and Sonja Horn, Data Scientist at EQT Ventures, explained how PAUSE is moving the needle in applying deep learning in the private markets. Let us quickly guide you through that.

Deep Learning for Competitor Mapping
Doing competitor mapping is vital in shaping a company’s strategies. This is usually determined by how similar the textual descriptions are. Many agree that automating the process for competitor mapping can save time and help identify companies that otherwise can be missed. This automation can be done with a trained model to output similarity between a pair of companies based on their textual descriptions, besides using public data that contains generic texts from sources. Training a model to understand company descriptions involves annotating the descriptors to indicate relatedness, and that brings another challenge.
Companies have access to enormous amounts of data. Still, only a small fraction of that is labelled, which is the challenge when applying deep learning in any real-world use case, including the private capital domain. That’s a problem because deep learning requires a lot of supervision signals.
“Let’s say we are looking at this company Acast and trying to figure out who the competitors are. There are a lot of possible candidates here but only a few known relationships. So the green line indicates we know that Acast and Megaphone are competitors, and the red line indicates that Klarna and Acats are not competitors. The rest of the relationships are unknown. And this is all based on textual descriptions. But the models can process text as it is. So we need some numerical representation of the text. This is called sentence embedding.”, explains Horn.
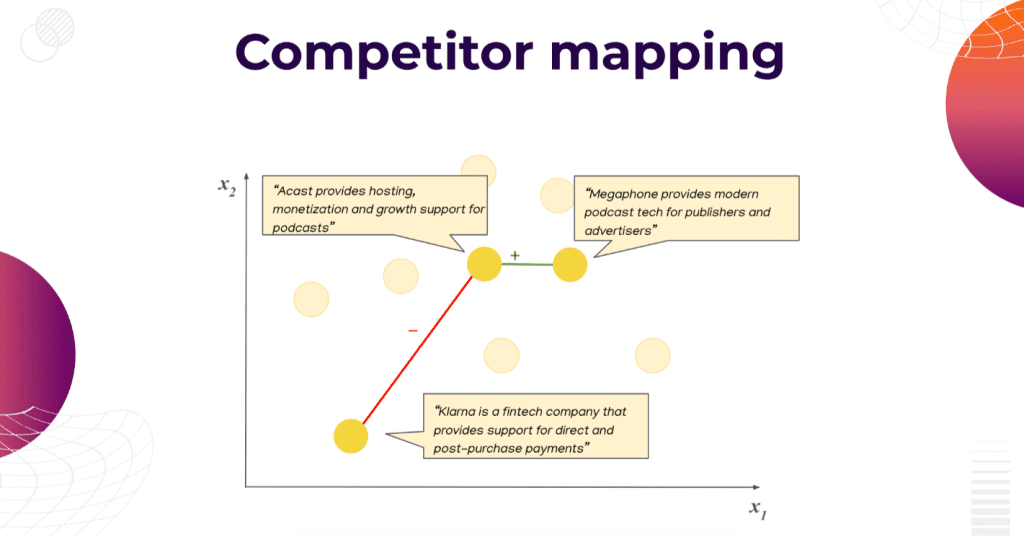
Sentence embedding is a numerical representation that describes the meaning of an entire sentence so that the distance between each sentence pair indicates their similarity. Company embeddings are numerical representations representing the company’s main business so that any two competitors would end up close to each other in the embedding space and different companies very far from each other.
How does a company go from text to embedding? A company Embedding Model maps competitors close to each other and different companies far from each other. The usual approach would be a dual-encoder model architecture, also called Siamese Model architecture—two identical sides of the model that share weights and handle one company description each. EQT uses a BERT encoder on each side, and those outputs are used for similarity calculation. The output of the similarity calculation tells the probability of these two companies being the same or different.
“In a perfect world, we would know the relationship between each company pair and have green lines and red lines between each pair of companies. Then it would be easy to train embedding company models because we’ll know the probability of each pair being the same or different. In reality, this is the data we are dealing with – we have some green connections in the competitors and some red connections in the non-competitors. Still, the majority of data is unlabeled, so we have a loosely connected graph, and the unlabeled pairs can not be directly used in training because we don’t know the probability of them being the same or different. We wanted to train a high-performing deep learning model to find competitors for any company we are looking at. We know that deep learning models perform best when they are exposed to a large number of labels. We had a lot of data but from enough labels until now. So we asked ourselves – How can we simultaneously exploit the labelled pair and explore the unlabeled sentences when we train a Company Embedding Model? That is how we came up with PAUSE.”, adds Horn.
How Model Training Works?
Before we share the explanation of how PAUSE works, it’s important to remind ourselves how model straining works in general:
“The model takes an input – X and some output – Y*, and to measure the quality of this output, we need to compare this output with some kind of ground truth label – Y, and sometimes we call this label the expected output. Usually, we use the loss function – L to calculate the difference between these two terms, and this calculated loss will be used to guide the model optimization later on. And usually the loss function there are many standard options as long as your dataset is fully labelled.”, explains Cao.
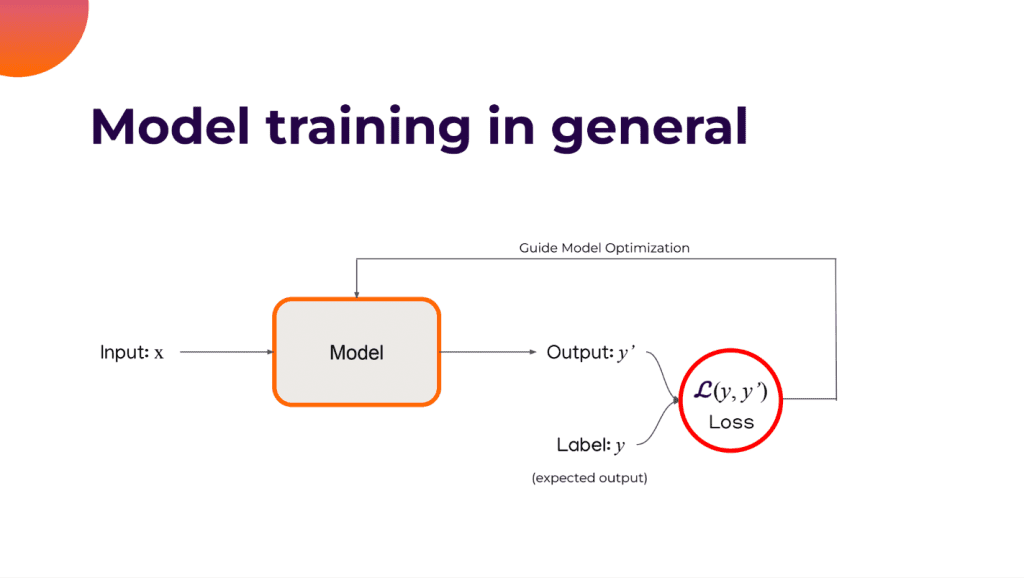
But what happens in case the data is not labelled?
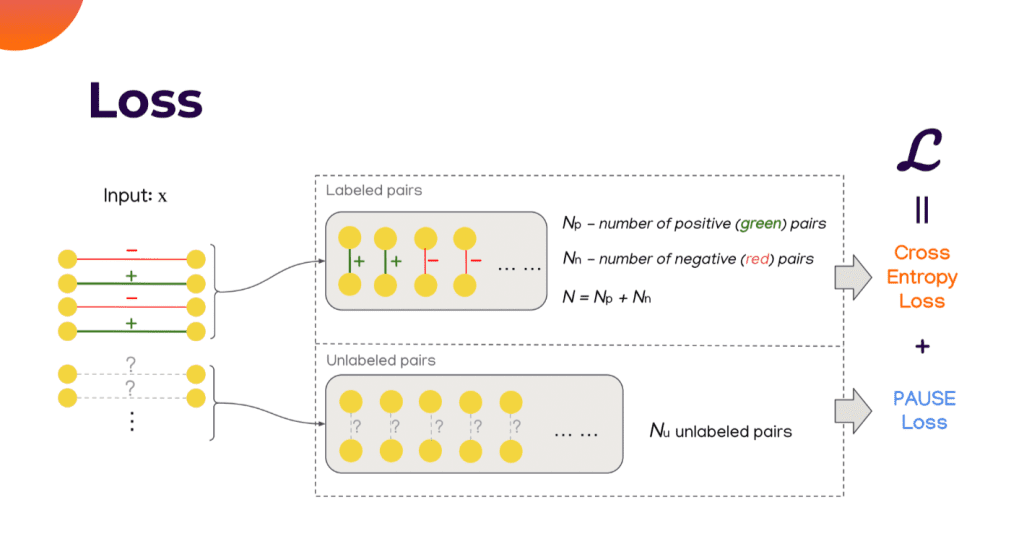
If you see Input X, there are different company pairs, indicated by the minus sign and similar companies, indicated by the plus sign. There are many where the relationships between them are not known, marked with question marks.
“And here we propose a divide and conquer approach: we first extract all labelled pairs into a dedicated part called – Labeled pairs. There are Np positive pairs and Nn negative pairs in total. We also take the unlabeled pairs from our dataset and call them – Unlabeled pairs, and in there, we have Nu unlabeled pairs. Now, we can use the standard Cross-Entropy Loss to calculate some loss terms for the labelled pairs. How about the unlabeled pair? This is not known. There is no ready-to-use loss function to calculate loss estimation for the unlabeled pairs. Here, this is the main contribution of our work. And we propose a special loss function called – PAUSE”, adds Cao.
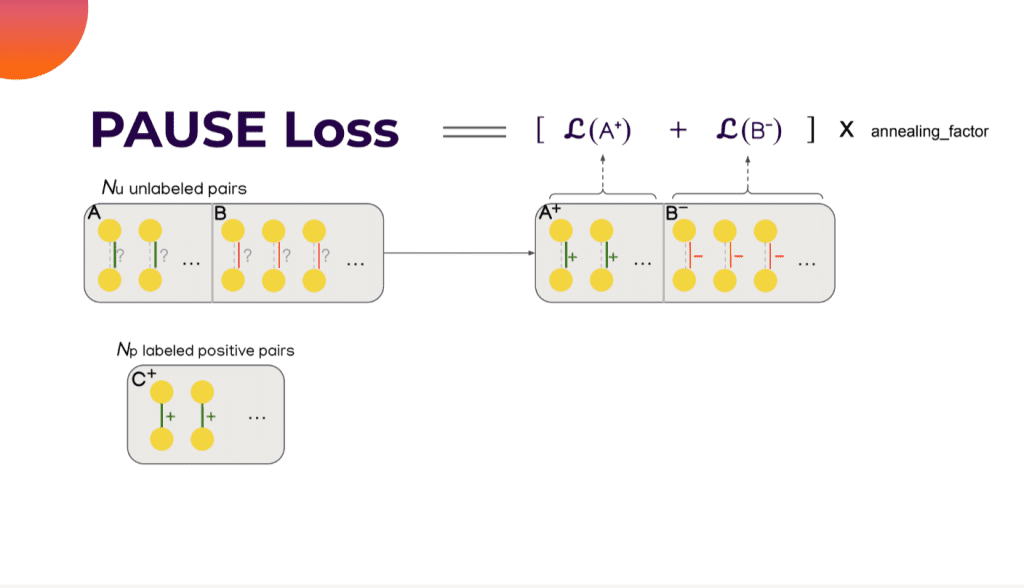
How Does PAUSE Loss Work?
PAUSE uses an entire dataset, not just annotated descriptors. This means that the model needs fewer supervision signals to successfully undertake the competitor mapping task. Also, with PAUSE, the competitor mapping can be completed in weeks rather than months, and it is not just improving competitor mapping. PAUSE can be applied to countless applications in private capital because it solves the most significant issue in using deep learning in the industry: the lack of annotations.
Can this term be used to do model optimization? Not yet, since the term can be a lousy estimation at the beginning of the training, and the term tends to get better as the training continues. That observation inspired EQT to add another term called the Annealing factor, which scales linearly from zero at the beginning to one by the end of the training. That means this loss will have a trivial impact on the training process, and the impact will gradually become normal. This is where the abbreviation comes from;
P – Np Paired positive pairs
A – annealing factor
U – Nu Unpalibled pairs and
SE stands for Sentence Embedding
Now, with this PAUSE loss and with the cross-entropy loss on the labelled dataset, the model can be optimized.
How Does PAUSE Work for Competitor Mapping?
EQT started with benchmarking PAUSE against state-of-the-art (SOTA) models. They compared the embeddings compared by SOTA models and those produced by PAUSE. All the compared models were trained on the same fully labelled dataset, but PAUSE uses only a fraction of the labels. Based on that, EQT got seven different PAUSE models, all trained on various percentages of those available labels. After this, the embeddings are evaluated on many benchmark datasets and downstream tasks. What was seen in their experiments is that not only PAUSE surpassed the fully supervised SOTA methods, but it also maintained impressive performance using as little as 10% of the available labels.
EQT has about 170K labelled company pairs to use. This is how the dataset looks:

“You have company pairs, textual descriptions and some labels indicating if they are competitors or not. We have here the same approach as in benchmarking. We mask a portion of the labels, and the resulting dataset is used to train different PAUSE models. It is sufficient to have 10% of the samples labelled and still reach high accuracy. This encourages us to extend our dataset with many unlabeled company descriptions without compromising performance. Why would we like to extend our dataset? We can always assume that deep learning models perform better when they are exposed to a lot of data or more data. On top of our 170K labelled pairs, we can add 1.5M unlabeled sentence pairs or company pairs and expect performance close to that of 1.7M labelled company pairs. We have a massive performance multiplier without any added effort. In terms of applicability of PAUSE, you can use it on any sentence embedding problem using dual-encoder model architecture.”, adds Horn.
Conclusion
There is much more to learn and know about how private markets can utilize ML and deep learning models. There is no better way to get to know how and follow the latest trend and expected developments than to follow the NDSML Summit. In November in Stockholm, we will hear exceptional practitioners with insightful presentations on the topic this article addresses. In the meantime, you can find the presentation by Sonja Horn and Lele Cao here. You can also read the research paper about PAUSE, for more technical information.
Featured image: Lukas Blazek on Unsplash












Add comment