
Data is the source of digital transformation, many agree. Managing, collecting, storing, protecting and processing data helps organizations to boost their business, optimize operations and improve decision-making. According to Mohamed Ashraf Ghazala, Data Architecture and Analytics Head at one of the leading Banks in Egypt, all modern data management should be unified/centralized, user-centric, cloud-based, built on modern data architecture, data governance boosted with ML/AI, flexible and cost optimized.
We are in an era of a massive collection of different types of data (structured and unstructured) through tremendous sources (internal transactions, sensors, mobile devices, social media etc.). However, for businesses leveraging data, that is not an easy task. There are several reasons. One is the unstructured data. According to Forbes, 95% of businesses cite managing unstructured data as a problem for their business. Another challenge is making decisions on bad data that can cost companies. Poor data quality costs the US economy up to 3.1 trillion dollars per year, according to Gartner. According to Forrester, up to 73% of the company data goes unused for analytics and decision-making.
The starting point of the digital transformation process is developing an effective data strategy that should be reflected in the organization’s business strategy, as well as proper data governance to develop and implement this strategy or modernize the data management. For many, modernization means transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data.
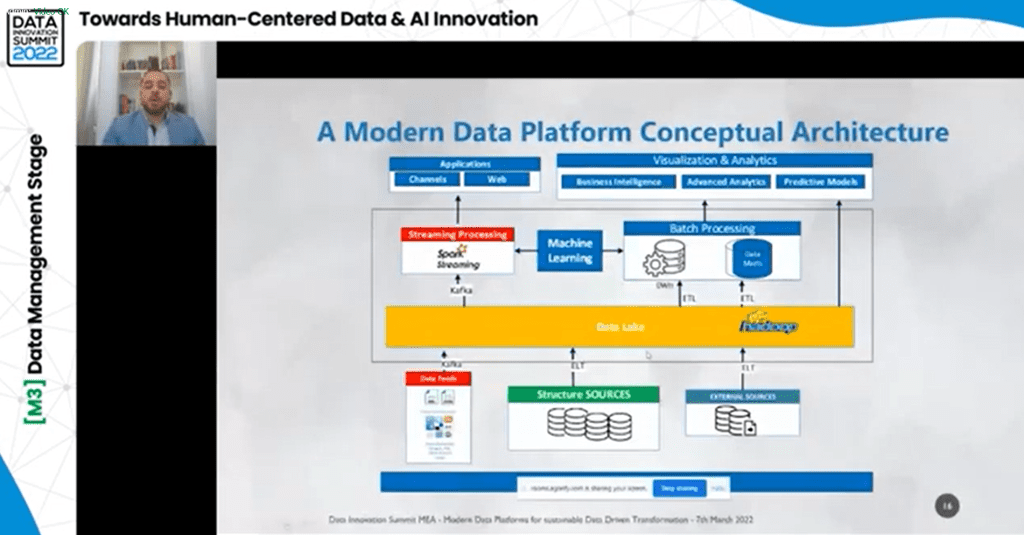
Data Lakehouse – What It Is and Key Characteristics
Organizations need simplicity in how they manage data. Based on this, organizations need simple data architecture. Also, many organizations use open source and open formats and plan for multi-cloud solutions. Because the amount of data that companies need to capture is massive, the data infrastructure is too complicated, and the governance managing that architecture, keeping all data sets up to date, becomes almost impossible. Most importantly, organizations need to move data outside on something like a Data Warehouse, where they need to combine the structured and unstructured data and be able to do ML and AI. According to Toby Balfre, VP Field Engineering EMEA at Databricks, these are the so-called four truths data, and AI leaders believe.

Where does this complexity come from? Balfre mentions several reasons for creating the warehouses and lakes complexity. One is that there are two separate copies of the data. Lakes are typically based on open source and open standards technology. The warehouse has a typically proprietary format. So the ability to connect those data sets is already a challenge. Another reason are the incompatible interfaces, as well as the incompatible security and governance models. These incompatibilities make it very hard to make a data layer that combines technologies.
But let’s go a step back and see briefly what exactly are Data Warehouse, a Data Lake and a Data Lakehouse.
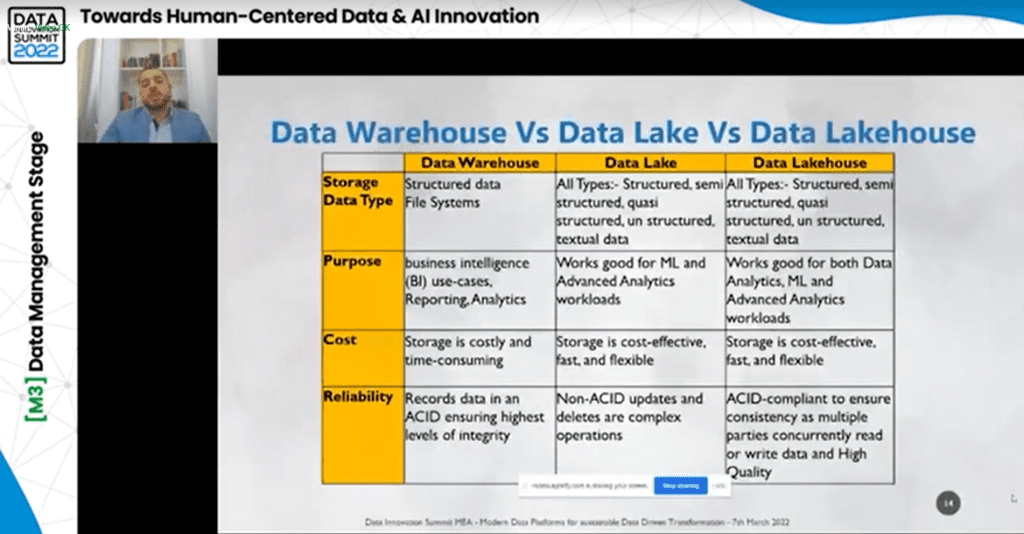
A Data Warehouse is for storing large amounts of information from multiple sources within an organization. A Data Warehouse extracts data from multiple sources, transforms and cleans it and loads it into the warehousing system. With a Data Warehouse, business analysts, engineers and decision-makers access data via BI tools, SQL clients, and other less advanced analytics applications.
A Data Lake is a centralized and flexible storage for large amounts of structured and unstructured data in its raw form (while the Data Warehouses store already “cleaned” data).
When you combine the best features of the Data Warehouse and management features for Data Lakes, you get the concept of a Data Lakehouse. It is a modern data platform, a single repository for all data types (structured, semi-structured, and unstructured); it is cost-effective for data storage and useful to data scientists as they enable machine learning (ML), business intelligence (BI), and streaming capabilities.
The key characteristics of a Data Lakehouse are:
- Data management features – A single platform for data warehousing and Data Lake is easier to manage than multiple-solution systems: a Data Lake, several Data Warehouses, and other specialized systems.
- Open storage formats – With open storage formats the data has a significant head start in being able to work together and be ready for analytics or reporting.
- Separation of storage and compute resources – The ability to separate compute from storage resources makes it easy to scale storage as necessary.
- Support for structured and semi-structured data types – Data Warehouses are not optimized for unstructured data types (text, images, video, audio). But Data Lakehouse can derive intelligence from unstructured data.
- Support for streaming – Many data sources use real-time streaming directly from devices and a Data Lakehouse supports this type of real-time ingestion compared to a standard Data Warehouse. Real-time support is becoming increasingly important as the world becomes more integrated with Internet of Things devices.
- Diverse workloads – A Data Lakehouse is an ideal solution for many different workloads within an organization, like business reporting to data science teams to analytics tools.
Snowflake talks about these additional features of Data Lakehouse:
- Concurrent reading and writing of data
- Schema support with mechanisms for data governance
- Direct access to source data
- Standardized storage formats
Benefits of the Data Lakehouse for Organizations
Data Lakehouse eliminates the costs and time of maintaining multiple data storage systems by providing a single solution. Data Lakehouses simplify and improve governance, allowing greater control over security, metrics, and other critical management elements. It reduces data duplication by providing a single all-purpose data storage platform to cater to all business data demands. Also, Data Lakehouses offer direct access to some of the most widely used BI tools to enable advanced analytics. Summarized, some of the benefits of the Data Lakehouse are:
- Lake first approach build upon where the freshest, most complete data resides. Organizations are still storing data in a cloud storage account and essentially a lake, and by doing that, they have all the benefits of the lake first approach, which is where they land all the different types of data and where they process that. With this, they have not just data science and streaming capabilities, but the BI and reporting can be done on the freshest data that is up to date. Often by the time data gets in the Data Warehouse, it is hours, days, or weeks old.
- AI/ML from the ground up – Organizations can start their lake house as a BI SQL structure data store, add unstructured data, and move into AI and ML without needing to train their data architecture. So you can evolve while still keeping it simple.
- High reliability and performance
- A single approach to managing data – Because organizations have all of the data stored in the same place, same architectural format and technology, all the security and governance challenges all balls into one. So they can have one attribute-based access model, and it doesn’t matter where they access it through Python, SQL etc., you can manage it in one simple way and one place.
- Support for all use cases on a single platform (data engineering, data warehousing, live time streaming, data science and ML). Organizations can ensure all the different use cases without moving data out, complicating the architecture, duplicating data etc.
- Build on an open source and open standards – Data Lakehouses use open-data formats with APIs and machine learning libraries, making it straightforward for data scientists and machine learning engineers to utilize the data.
Challenges of the Data Lakehouse
One of the most often mentioned challenges is that Data Lakehouse is still a new technology; and based on that, it is not certain whether it will reach what many hope to achieve. Many agree that it will be years before Data Lakehouses can compete with big-data storage solutions, and that data engineering teams need to master new skills associated with running metadata management. Also, data scientists need to learn new skills to benefit from the new architecture.
In 2018, Annika Nordbo, Head of eCommerce Data and Analytics at SOK (previously Head of Data and Analytics at VR Group), told the story of VP Group that will help you better understand the challenges and benefits of having a one combined solution for a Data Lake and warehouse simplified architecture, or building a data and analytics platform from scratch, that can bring a business value.
The company had old data architecture. There was a need to build a lean analytics function with data, BI and data science quickly. The company started by recruiting and forming a data team: a data scientist, analyst, BI developer, data engineer and data architect. They started planning new data architecture and building a data and analytics platform. What the company did is the team collected all the data together and refined it, using data science to make it smarter. Then, they push the data to the business via BI tools and API personalized content and to operative systems that need later on customer service. How to keep it lean from a technical perspective, built so that each part can be taken out and the thing doesn’t collapse? The company:
- Started building cloud infrastructure
- Used open source tools for the data pipeline and data science
- Chose cost-beneficial analytics applications for the business
- Built a warehouse solution that solved almost all problems
“First on the list was the warehouse to be scalable and have no concurrency issues. The storage and computing are separable, which means data lies in one place, and “virtual warehouses” are created for different user groups. These warehouses can be of different sizes and auto-resume/suspend. This decreases the cost because we don’t have a big warehouse running 24/7. Another requirement was the ability to load semi-structured data directly into the same platform. For this, there is no need for a separate Data Lake, and this ability saves the developer time. Virtual warehouses seem like any warehouse that can be queried with SQL. So even if there is a structured and semi-structured data mix, we can still use SQL to get it out. What we could do is that we didn’t need to build a Data Lake and a warehouse. With the solution we acquired, we could get different data and do it together, saving time and money and keeping the architecture simple and easier to manage. The next requirement was connectivity. Often there is the problem where you can make a great data pipeline, but when it comes to people using the data, there are problems. We wanted a BI tool that is scalable and cost-efficient. For this, we need a warehouse on the back that can handle this. Another requirement was minimal management. We didn’t need to install software, update it, have infrastructure etc., and we could concentrate on bringing value out of data. This also allows us to focus on security.”, explains Nordbo.
With this approach, VR Group has been able to do data science helping with corporate travel, shift planning, product pricing strategy and loyalty program development.
Solutions in Establishing Data Lakehouse
Some of the solutions when establishing a Data Lakehouses can be to:
- Develop a data governance plan. This plan should clarify who has access to which data but also explain who is responsible for maintaining the data and how the data will be cleansed and standardized.
- Create a data catalogue. It helps people find and understand the data stored in the data lake. The catalogue should include information about the data, such as the source, format, and schema.
- Choose the best data platform. It is essential for managing an effective Data Lakehouse. It can be cloud, hybrid or on-premises.
- Clean the data. The quality of the data, and the assurance that the data is accurate and trustworthy, is a crucial aspect of a Data Lakehouse.
- Use big data analytics tools. They should include features for data exploration, visualization, and ML.
What Is Next?
Can we expect new trends and developments for organizations to follow? For sure. And the upcoming events that Hyperight organizes are a perfect opportunity for you to get to know first hand. In September in Stockholm, the Data 2030 Summit happens. It addresses the latest data management challenges and solutions. In November, the 6th edition of the NDSML Summit happens. You will hear the newest updates for data scientists and enthusiasts there.











