
“It is a common missing misconception that Scania is one company. It is really a group based on hundreds of companies in different markets and countries all over the world. This comes with a specific set of challenges, because we are sitting in different parts of the world, we have different cultures, and we work differently. For this reason, we must establish a very solid foundation and infrastructure to enable data sharing.”
Georg von Zedtwitz-Liebenstein is the Information & Analytics Lead at Scania Financial Services, whilst he also has previous experience as a Senior Data Scientist within Scania’s Connected Services and Solutions department, so he is very familiar with these challenges and opportunities! It is a hugely significant time to be at Scania as they work towards their 2025 Strategy and their vision for a sustainable transport future. This transformation, much like many others, is being fuelled by the ever-increasing volume of vehicle and mobility data. Estimates state that vehicles on the road generate more than 30,000 petabytes every day. With these exploding information volumes, it is crucial that you have an efficient AI Foundation and this fundamental core, driven by the underlying quality of your information, is what we focused on during Episode 5 of the Future Says Series.
Data is like blood in our bodies and high-quality data keeps our businesses healthy. However, according to IBM, bad data costs the U.S. economy $3.1 trillion per year, while Gartner states that it can cost organisations an average of $12.9m per year. No matter what stage of the digital journey you are at – whether you are still focused on reporting, building out dashboards, or implementing advanced AI – it all comes back to trusting your underlying foundations. If you cannot trust your information, you are simply not going to get very far. Despite the advances that have been made in ML and AI in recent years, many companies are still not using it to make operational decisions because business leaders do not trust it. According to the 2021 Gartner Summit, 90% of leaders are still using ‘gut feeling’ to make decisions. This past year provides ample evidence of this. As the world was under siege by a deadly pandemic, we started questioning the trustworthiness of scientific research institutions and governments while statistics about case numbers and death tolls were constantly queried.

Additionally, low quality information will affect your business operations from a concrete financial standpoint and, as regulations continue to evolve, it has become increasingly important that companies prioritise data quality and management. As we all know, AI models are only as trustworthy as the data they are built on, and with the growth in the volume, velocity, variety, and veracity of information, it is becoming exceedingly important to establish a solid foundation to track the lineage of your information. Bad data hinders getting the desired insights and erodes confidence in what your analytics teams are doing. Whatever the case, whether it is internally with lines of business, or externally with customers, low data quality has long-term effects on the reputation of data and the people who take care of it. Here are some more statistics to further indicate the growing importance of this type of foundation:
- According to Datanami: 90% of AI projects fail due to a lack of good or appropriate training data.
- According to the Information Age: 84% of organisations see their analytics projects delayed due to the data not being in the right format and, for 82% or organisations, the data used is of such poor quality that analytics projects need to be entirely reworked. More statistics from this report are illustrated on the following diagram.
- According to the IDC: By 2023, 50% of the Global 2000 will name a Chief Trust Officer and, by 2025, two-thirds of the Global 2000 boards will ask for a formal trust initiative with milestones aimed at increasing an enterprise’s security, privacy protections and ethical execution.
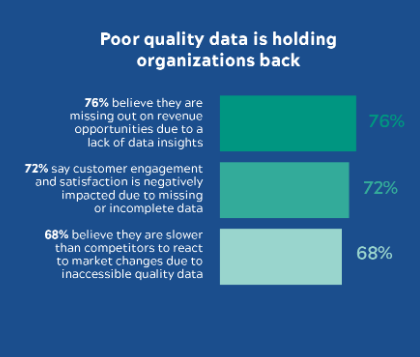
A lack of data quality may exist for numerous reasons. Organisations failing to recognise its importance, technical gaps in the foundations, or siloed information which is inaccessible to the right people at the right time, comes to mind as possible reasons. However, according to Experian, the top reason for information inaccuracy is human errors. Remember that over 88% of Excel spreadsheets contain errors according to Forbes.
There are numerous factors that contribute towards data quality – accessibility, accuracy, completeness, consistency, relevancy, validity, timeliness, and uniqueness. Uniqueness is the most addressed dimension, when dealing with customers, as this can regularly be tarnished with duplicates. Similarly, duplicates and inconsistent data in financial reporting, can mean different answers to the same question leading to disastrous outcomes for some companies.I would recommend checking out this link for a deeper dive into the different components which make up data quality.
The remedies used to prevent quality issues include functions like governance, profiling, matching, cleansing, and data quality reporting. Go to any AI conference and you will see many vendors speaking about their solutions in these areas. However, improving quality must be an enterprise-wide initiative encompassing people, processes, and partners. This trio of ingredients is what I will focus the rest of this blog on – incorporating Georg’s expert feedback based on his own experiences at Scania.
Required Partners
In data quality management, the common goal is to prevent future issues and to cleanse (or ultimately eliminate) information that does not meet the quality KPIs. These KPIs should be measured in relation to the dimensions mentioned above and should also relate them to the KPIs used to measure overall business performance. When starting out, you must identify the quality components that need fixing and start developing standards and partnerships to improve them. At Scania, Georg mentioned that they have:
“Common principles and standards to details how we can share data, build different data products, and join data from different parts of the organisation. Of course, we should measure it, and understand if we have good data or not, but then we should also take a step back and ask what makes good data? What can we do to achieve high quality information that we can take business critical decisions on?”
It is impossible to scale the data quality initiatives without right tools and you should manage these solutions as part of your overarching governance framework. Technology maturity is doing the right thing not necessarily doing the latest thing and investing in your AI Foundation before investing in analytics is oftentimes very crucial. For example, some organisations I have spoken to find it useful to operate a basic data quality dashboard highlighting the KPIs and the trend in the issues going through the log. At the end of the day, companies’ investments in AI will not yield a good return of investment without first sorting out your foundations and you must convince senior management of this. Whatever you decide to implement, I would stress that it should be self-service, code-free and easy-to-use. Without this, your quality initiatives will likely fail during the People and Processes phase. Scania are also looking towards partners at this juncture:
“Scania has a very proud history of being self-sufficient and developing things in-house, but in order to be fast, we need to do this together with partners. We are seeing more and more external collaborations nowadays.”
Required Processes
As always, the first step of the process is simply knowing where to start. You should focus on data quality ‘hotspots’ that will have the greatest impact on your organisation. You should minimise the risk by minimising the target. Explore and protect the information you need, and only the information you need, and eliminate the rest. Drafts, duplicates, and outdated information should be erased. Low-value data not only creates unnecessary risk, but it also makes it harder to locate and utilise the information you really need.
However, achieving good data quality is a continuous and iterative effort. Do not be deceived by the idea that this is one-time operation and that you can clean it once and then forget about it. Fixing these issues must be cyclical. With this rapidly evolving space, I would advise not to plan more than three years ahead and to leave your priorities open to change in the future. Melody Chien, Senior Research Director at Gartner, summarised her presentation at this year’s summit (which included the following image) into ‘what works’ and ‘what does not work’ when it comes to quality initiatives. According to her, big bang projects which are primarily IT-driven do not work. Starting with one project in a manageable scope and being proactive around collaborating across the enterprise does work and I am seeing these same trends in my conversations. Georg agrees:
“Start small – we cannot transform the entire company at once but the most powerful thing you have is to actually do something and then tell others about it. Furthermore, the earlier you start, the less legacy you need to change. Try to be early, work fast, start small, prove the value, and then choose a direction to go and be comfortable with that not being the direction forever.”

From a functional, end-user process perspective, you should also ensure you can check where a record has been and who has accessed it throughout its journey within your systems. A detailed audit trail should be provided. However, from my experience, confronting quality issues is as much about changing behaviour as it is about providing technical solutions. Errors typically occur when the data is first captured so you need to work with the creators to ensure improvements are made during this capture process. The quality issues will only go away if you address the root cause of these issues. Georg summed up the required process and mentality with the following quote:
“The important thing is to understand that we are learning all the time, and we need to have a process that is responsive to change. We need to change along the way and design the process for that to be possible. I think that we have a great culture at Scania, and it is really based on autonomy and distributed leadership.”
Required People
Much like AI, data quality is a team sport and you must define roles and responsibilities upfront to build skills and competencies. As a result of the well-documented skills shortage and talent frenzy, I believe the most important factor in this transformation is education and looking internally to your existing employee-base. You need to make people care by connecting business impact to data quality. You need to disperse responsibilities via a ‘Hub and Spoke’ approach and ensure a collaborative, data-driven culture is developed. In Scania:
“I think a lot of these competencies might already be present within your company. In many cases, they might be called something else, and might have a different responsibility today, but they should shift towards becoming data product owners.”
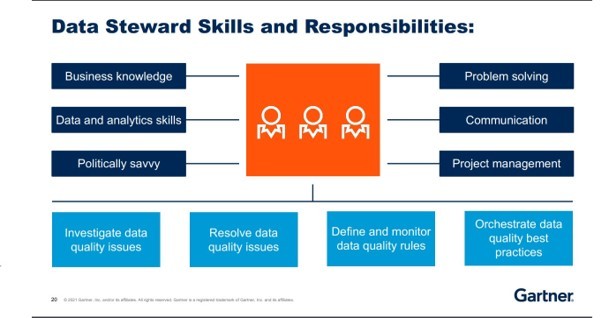
Your plan should define the roles of all personnel involved in data collection and establish processes for cross-departmental communication on these matters. Roles such as data owners, stewards, and custodians, can all make sense in any given organisation. As seen in the following diagram, provided by Gartner, a data steward’s role should be to:
- Investigate data quality issues
- Resolve data quality issues
- Define and monitor data quality issues
- Orchestrate data quality best practices
To hear more about some of the newer roles within data, check out my previous blog, in collaboration with H&M, about Amplified Intelligence. As Georg said:
“First and foremost, you need to create this very clear ownership of your information. Who wants to take ownership of something that a central team put in a data lake that you do not really understand? We have really adhered to this data products way of thinking. In order for someone to take this responsibility and ownership, they must have the end-to-end responsibility and ownership of it. You can’t just outsource that to another part, you can’t just dump your source system in a central lake and think you’re finished. That is not how an efficient data landscape looks right. We need to think similarly to the microservices movement in software.”
This is episode 5 of our Future Says Series and we have already spoken about a number of different areas to invest in – Amplified Intelligence, Responsible AI, AI for Social Good etc. However, the common thread throughout all of these topics is the requirement for good data quality. Accordingly, to cut through the constant noise about what you should invest in, my Year One Strategy advice is to focus on two things – data quality and data literacy. With this solid foundation, the possibilities and opportunities are endless.

If you agree, here is a useful guide provided by PWC, which documents some of the key questions to ask before embarking on a data quality improvement programme:
- Is data treated as a core asset at board level?
- Who is currently in control of your data assets and processes?
- Do you understand which teams are data creators, and which are data consumers?
- Are data creators aware of the needs of data consumers?
- Is maintaining high data quality aligned with team objectives?
If you would like to watch this episode in full, check out altair.com/futuresays.
About the author

Sean Lang is the founder of Future Says – an interview series where he debates the pressing trends in Artificial Intelligence alongside some of Europe’s leading voices in the field. At Altair, Sean is helping educate colleagues and clients on the convergence between engineering and data science. From his background at both Altair and Kx Systems, Sean is passionate about championing data literacy and data democratisation throughout the enterprise. He believes in a future where everybody can consider themselves a data scientist.




