
Jayesh R. Patel, Sr. Data Engineer at Rockstar Games, will be presenting at the 5th edition of the Data Innovation Summit on the topic Scalable Big Data Modeling on the IGNITE Stage. This article is written by Jayesh Patel as part of his speaker participation at the summit.
Background
Big data analytics leveraged Artificial Intelligence (AI), Machine learning (ML), and Deep learning application in recent times. ML application adoption is not limited to certain industries. As more and more enterprises are jumping on the ML boat to gain a competitive edge, it would be fruitful to share some of the best practices to consider while strategizing ML vision. ML journey may not be smooth as pictured in theory. A variety of data sources are accessible in enterprise big data lake. However, ML application development can be time and resource-intensive. Data scientists and ML developers still spend most of their time in data cleansing, feature extractions, and modelling for ML applications repeatedly. The state of ML development didn’t change much since the last time NY times took the survey which revealed data scientists and developers spend 80% of their time in data wrangling. It not only impedes the ML application development but it also negatively impacts overall consumer satisfaction and the enterprise decision making. Mr. Jayesh Patel, an Expert Big Data Professional and Machine Learning Architect, shares his expertise and visionary advice on a way to overcome these challenges.
Machine Learning Development and Challenges
In January 2018, the Gartner Data Science team conducted a survey on Data Science and Machine Learning platforms and current development processes. One of the interesting findings was that over 60% of models built with the purpose of operationalizing were never actually completed. You may find so many enterprises jumping on having a strategy to develop ML applications, but they usually end up with Business Intelligence solutions. The problem resides in the understanding of the ML development process. Figure 1 shows the typical development cycle for machine learning application development.
Most of the steps such as identifying a business problem, data collection, ETL/ELT, model training and validation, deployment, and monitoring are self-explanatory except Feature Engineering. Feature engineering is one of the most time-consuming phases in ML development and it requires maximum resources.
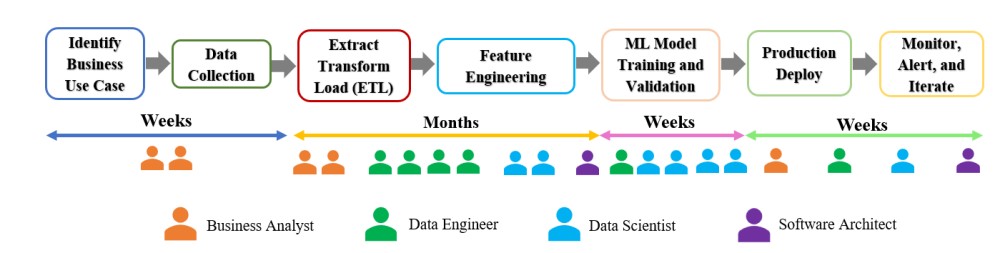
Big data is often integrated, cleaned, transformed, and stored in big data lake before being used in ML applications. This process of transforming data for ML applications is known as feature engineering. An ML feature is an attribute or individual column useful to an ML problem. ML Feature, an integral part of ML applications, directly influences the predictive models. It is wise to say that better ML features lead to better results. Features often require thorough cleansing, intensive computations, or aggregations over the period. Often, data engineers, machine learning developers, and scientists repeat these steps even though they use the same data. Features usually stay in a silo and not shared among the team members. Imagine you developed a great product after working for days and you are the sole user. What’s the use if you are the only user of your product!
Moreover, As ML algorithms learn the solution of a defined problem from sample data, it is imperative to make curated data available in the enterprise. Results from poor, inconsistent, and erroneous features can ripple across the organization. It further leads to downstream problems and adversely affects critical enterprise decisions. That is one of the key blockers to achieve success at ML development.
To ignite ML Development and conquer these challenges, one of the effective ways is to centralize ML features and serve whoever needs them in a unified way. Sharing cleaned and processed ML features will not only save time but also leads to better predictions. That is the central idea of ML Feature Store.
ML Feature Store
A feature store is a centralized place for storing curated and access-controlled features that are ready to use for ML applications. It is like the classic software dilemma: buy or build your own. Developers and scientists can build their own features, or they can get these features ready from a feature store. They will spend more time in the first approach, and they will lead to inconsistent features. An enterprise feature store incorporates numerous features across discrete business verticals. It serves these features to all users as needed without reprocessing them.
Uber pioneered the concept of ML Feature store to manage shared features used in offline training and online servings. Later, Airbnb, Google, and others built similar feature stores to democratize ML features. As more on more enterprises started ML development, they too felt the need for ML feature stores.
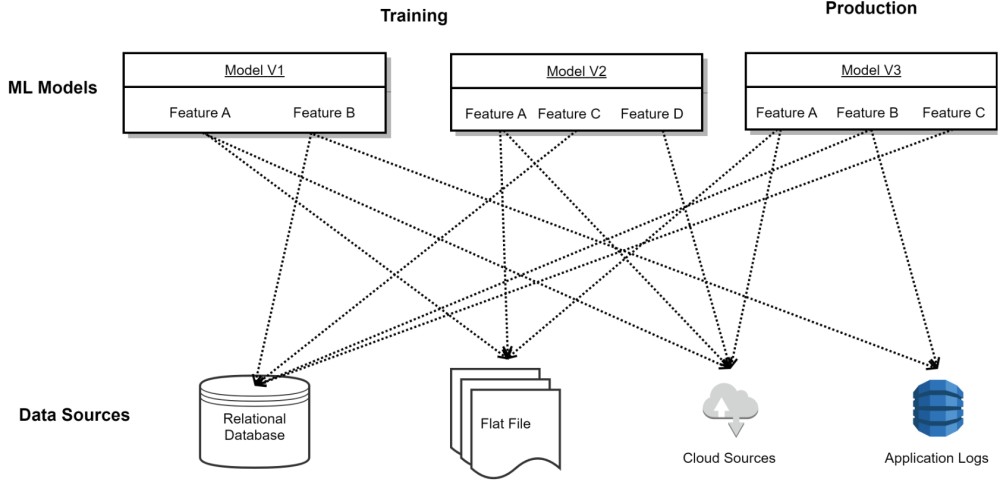
Every ML project starts with collecting the right set of features. Many features are processed and tried to generate tuned ML models. Figure 2 shows a typical use case of how ML models are built without a centralized feature store. It demonstrates that numerous features are used for multiple models. However, there are some common features being used. Common features are recomputed every time they are used. Moreover, training and production pipeline needs to be in sync to generate an expected outcome.
Feature store stimulates ML application development by abstracting feature engineering layer to enable easy access to all features. Figure 3. shows development with an enterprise feature store. All ML features are shared using a feature store. They are computed once and are available to all users anytime they want.
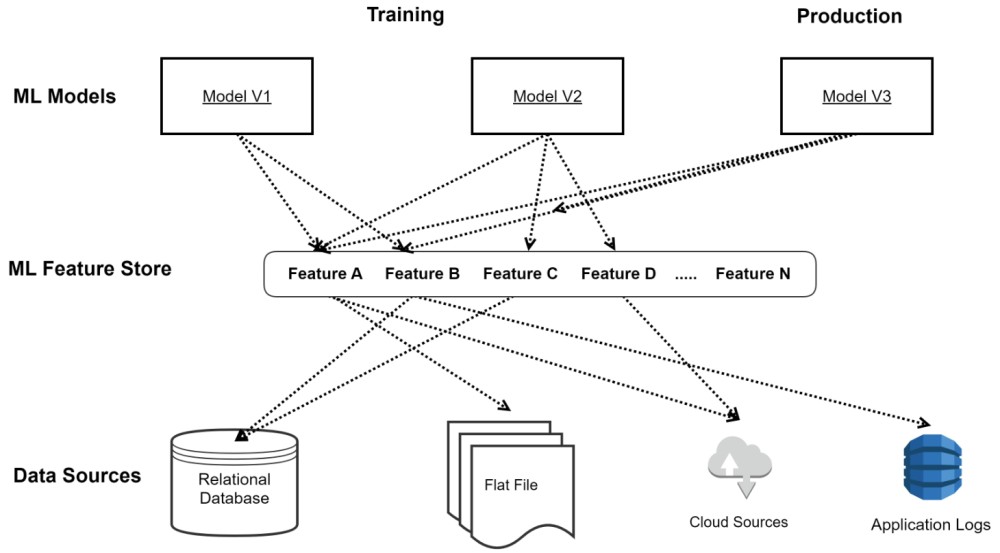
ML Feature store facilitates feature democratization and it provides several benefits. Implementation of feature store or democratization strategy might vary for different enterprises. However, the core idea remains the same. It requires a significant effort from development and operational teams to create a feature store. However, once a unified platform is there, developers, analysts, and scientists will not spend time repeatedly on the most time-consuming part of the machine learning development process.
Summary
Data-driven processes and ML applications increasingly became popular in recent times. To stimulate ML development, enterprises face several challenges such as analytics silos, inconsistent training and production pipelines, failures to operationalize ML applications, too many steps, and numerous iterations, etc. Feature engineering, a time-consuming and resource- intensive process, causes most of these issues as it feeds features to ML applications. Feature store facilitates a unified abstraction layer to share features to fuel ML development. Enterprises can leverage their ML strategy using a feature store to solve challenges around feature engineering.


