
Data Science is a wide-ranging field situated at the intersection of Analytics, Statistics, Machine Learning, and Artificial Intelligence. Creation of a valuable product is a gradual process that involves cross-team communication and working closely with different stakeholders, such as Product Owners, Project Managers, clients, or end users – Figure 1.
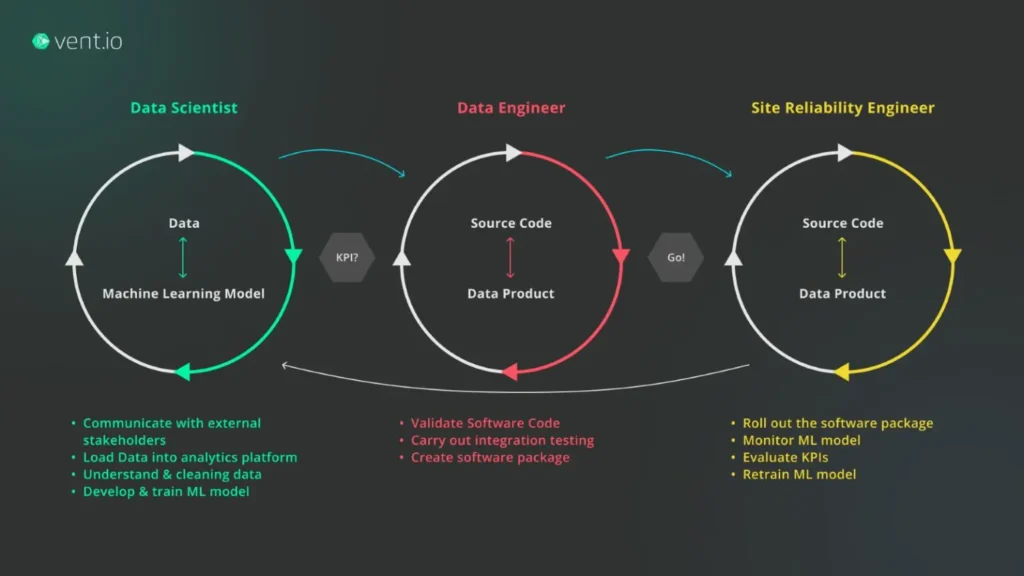
The common starting point is based on business goals, which sometimes may be stated more like business “hopes” rather than exact requirements. In such scenarios, it falls upon the Data Scientist to determine how to transform these wishes into valuable outcomes. While Data Scientists typically measure the success of their developed algorithms using statistical metrics like accuracy, MAE, etc., the ultimate metric influencing decisions is Value. The pivotal question revolves around
“Whether the proposed solution delivers tangible value to the client or end users”.
This article seeks to emphasize the significance of collaboration in enhancing the decision-making processes in data science. Therefore, we focus solely on the initial phase of the product development cycle – Data Science, Figure 2. We illustrate our point by presenting real-world examples, demonstrating how we tackled uncertainties, and showcasing the strategic selection of a proper algorithm that successfully provides substantial value to the end users.
Problem Statement
At vent.io, the digital and innovation branch of Deutsche Leasing, we assist German SMEs in accelerating their growth. Deutsche Leasing is the largest manufacturer-independent leasing company in Germany. Our mission is to provide digital solutions that assist Deutsche Leasing’s customers; for example, by helping them select the best financial option or by giving them more clarity on their needs through visibility in their financed assets.
We have recently embarked on a project with the sales business unit of Deutsche Leasing. Their responsibilities involve processing a substantial amount of information from diverse sources to gather relevant data for their needs. 
One of the most significant sources of this information are the websites and annual reports of German companies, which, from a data scientist’s perspective, primarily comprise numerical and textual data.
Processing financial statements is relatively straightforward due to their quantitative structure. However, extracting valuable insights from textual information presents a significant challenge due to its inherently ambiguous nature. Therefore, in this article we focus on textual information and elaborate on our reasoning process, which resulted in valuable features incorporated into our Sales Assistant solution.
Tools at Hand
Before diving into the examples of features we have developed, let us address a common question which naturally arises:
“Which methods should be employed to address a specific problem?”
To answer this question, we must first comprehend the tools available to us.
A) Numerous techniques in Natural Language Processing (NLP) are available for tasks such as Named Entity Recognition (NER), Sentiment Analysis, Summarization, Text Classification, Translation, and more.
B) Generative models, such as Large Language Models (LLMs), including those developed by OpenAI, Cohere, and various open-source LLMs like LLaMA or Mistral. They recently have gained significant attention and found numerous applications in business. These models showcase remarkable textual comprehension abilities and can multitask, providing the full functionality of standard NLP techniques. In addition, they can be enhanced, for example, by being part of a Retrieval-Augmented Generation (RAG) pipeline. This, in particular, helps to reduce hallucinations—a phenomenon where LLMs may produce incorrect information.
Understanding the pros and cons of these methods is crucial for making informed decisions. The classification of these techniques depends on the perspective from which we examine them:
- One-task vs multitask algorithms: while some models are pre-trained on a specific task, the LLMs can be used for various purposes.
- Generative vs extractive: LLMs are better suited for tasks that require creativity and human-like response, while extractive methods are used in the applications which require accuracy.
- Execution time: hosting and deploying an open-source LLM requires significant efforts and costs, so simple and lightweight models are preferred over.
- Data Governance: usage of LLMs can be provided via commercial APIs which solves the deployment problem. However, this might have additional data governance limitations.
Collaboration is the Key!
Upon obtaining a thorough understanding of the available options and their respective areas of applicability, it is time to apply the appropriate method to our problem. However, questions such as
“What problem are we trying to solve?”
and others will arise throughout the development cycle. In order to address them, we maintain a development process which is characterized by high iteration and comprises four key components: Question, Action, Response, and Thought – Figure 2 (our own interpretation of CRISP-DM).
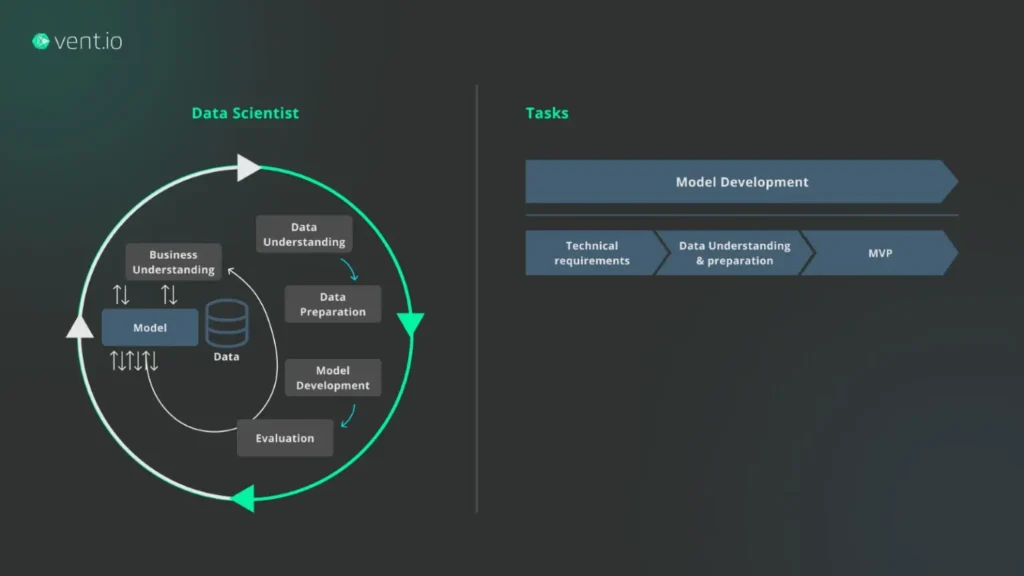
An illustrative example of one iteration is presented below:
- Question: The solution must effectively address the end users’ problems and needs. What problems do they have, and how can we solve them?
- Action: Engage with the end-users to comprehend their day-to-day workflows and identify their needs and challenges.
- Response: The actual problem we aim to tackle is the need to minimize the time spent on reading and searching for valuable information.
- Thought: A potential solution could involve creating a summary of the annual report.
How Collaboration Shapes our Decisions
Intense and close collaboration with the end users has influenced our strategic decision in selecting the appropriate algorithms for the challenges at hand:
- We have developed a comprehension of the nuances among different information sources and how the end users utilize them.
- This has led us to formulate specific requirements tailored to each information source.
- The evaluation of the advantages and disadvantages linked to various NLP techniques has further guided informed technical decisions for our approach.
Let us showcase the results of this collaboration through examples of two distinct sources of information: the company’s annual report and the company’s website.
Source 1: Company’s Annual Report
Typically, annual reports include textual information such as business overviews, management discussions and analyses, risk factors, corporate governance details, and other narrative sections.
Several constraints guide our approach, including:
- The client’s interest in specific topics like sustainability or supply chains.
- The necessity for a Topic-Targeted Summary rather than a simple compressed version.
- The requirement for consistent output for each user with every request.
- The prioritization of accuracy over creativity.
These requirements have led us to the decision to favor Semantic Search over the use of Large Language Models (LLMs). Semantic Search represents an advanced search approach that, when given a query, identifies relevant pieces of text that are semantically similar to the query. This choice ensures that results remain consistent with each request. Another key advantage of this approach is its extractive nature, meaning that the results consist of exact snippets from the original text.

Source 2: Company’s Website
Another source of information the end-users often need to deal with are companies’ websites. One of the primary objectives of utilizing website information is to enrich data sources where information is missing or incomplete. This for example includes details about board members, contact information, or branch locations. In this example, we illustrate the process of gathering information to compile a business overview for a company.
The constraints for this task are relatively lenient comparably to annual reports:
- The client requires a concise business overview for the company.
- The overview should be brief yet offer general insights into the company’s operations.
In light of these requirements, the optimal choice is to employ a Large Language Model (LLM) within the RAG pipeline. In this pipeline, a retrieval component extracts relevant text snippets from the entire website. These snippets are further fed into the LLM, which summarizes the information and generates a concise business overview.
Does it Really Bring Value?
Finally, the development process is done, the product is delivered and the Product Owners are happy. However, even in this scenario it is crucial not to cease communication. We certainly want to avoid a situation where our solution is of no use after just several months. To prevent this, several options are available:
- Tracking users’ activity
- Establishing a feedback loop, for example with thumbs up/down: 👍/👎
- Conducting periodic surveys on users’ satisfaction and their preferences.
We are currently in the process of evaluating the value and necessity of each one of those options. Hopefully some or all of those can help us understand whether the delivered product not only holds theoretical value but also proves beneficial in practice.
In Conclusion
The real-world examples presented in this article illustrate that collaboration and iterative feedback play a crucial role in addressing key questions:
- What is the actual problem we are trying to solve?
- What technique, algorithm, or approach should be adopted?
- How should the solution appear in its final form, and what user experience must we ensure?
- What metrics are relevant, and what values are deemed desirable?
By showcasing the significance of collaboration in these decision-making processes, we hope to highlight its power in navigating complexities and achieving meaningful outcomes in the field of data science. Because what truly matters in the end is whether the provided solution brings value.
About the Author

Sergei Savin is a Data Scientist at vent.io where he develops digital solutions for various business units. Sergei holds a Ph.D. degree in Theoretical Physics and has an experience spanning various industries and areas of Data Science. What truly excites him is unraveling complexity to deliver tangible business value.
Moreover, Dr. Sergei, along with Georgios Gkekas, Chief Technology Officer at Vent.io GmbH, will be presenting on “From Python Snippets to Production-Ready ML Models: How to Streamline and Trust Your ML Models in Production” at the upcoming Data Innovation Summit 2024. Delving further into their presentation, Georgios Gkekas, Chief Technology Officer at Vent.io GmbH, elaborates during a recent interview.
For the newest insights in the world of data and AI, subscribe to Hyperight Premium. Stay ahead of the curve with exclusive content that will deepen your understanding of the evolving data landscape.











