
In recent years, large language models (LLMs) have become a catalyst for revolutionizing human understanding. With vast linguistic knowledge and adept context understanding, these AI systems offer endless opportunities for enhanced acquisition and cross-cultural understanding.
In this article, we cover some of the multifaceted applications of LLMs, exploring their impact across diverse domains ranging from education to communication and beyond.
Throughout our exploration, we highlight some presentations at the Data Innovation Summit 2024 – presentations that offer insights into the groundbreaking work being done in each respective field. Join us as we dive into the power of LLMs and the possibilities they bring to our world!

Maximizing the Potential of Large Language Models
Diving into the depths of large language models, one might wonder: how do we fully unlock their potential? Unlocking LLMs’ potential starts with quality datasets matching the application. Fine-tuning architecture, parameters, and using techniques like transfer learning enhances task performance. Ethical considerations, like bias mitigation and responsible use, are crucial. Moreover, collaborative research propels progress in this field.
Excitingly, this topic is just one of the many highlights at this year’s Data Innovation Summit. Don’t miss the opportunity to gain first hand insights from industry expert Thomas Capelle from Weights and Biases, as he reveals ways of getting the maximum performance out of these tools!
The Importance of Evaluation for Large Language Models (LLMs)
Why are evaluation techniques crucial for developing LLMs in the age of AI? How do these techniques ensure the effectiveness and reliability of LLMs?
As the forces of AI shape our future, rigorous evaluation techniques are indispensable for the development of large language models (LLMs). These sophisticated models hold immense potential, but their efficacy needs rigorous testing to ensure responsible and effective development.
Recognizing this crucial role, this year’s Data Innovation Summit is excited to announce the presence of industry expert Rajiv Shah, who will be discussing evaluation techniques for LLMs. Bringing his expertise to bear on this topic, he will shed light on how we can assess these language models. He will also discuss strategies for optimizing them for the benefit of all.
”As AI grows in complexity, it’s more important to ensure it’s actually solving the problem that we care about. Too often, people grab the latest technology. However, a mismatch between its capabilities and end users’ needs hinders widespread usage. Evaluation is a crucial link that helps in building more useful models in less time.” states Rajiv in a recent interview.
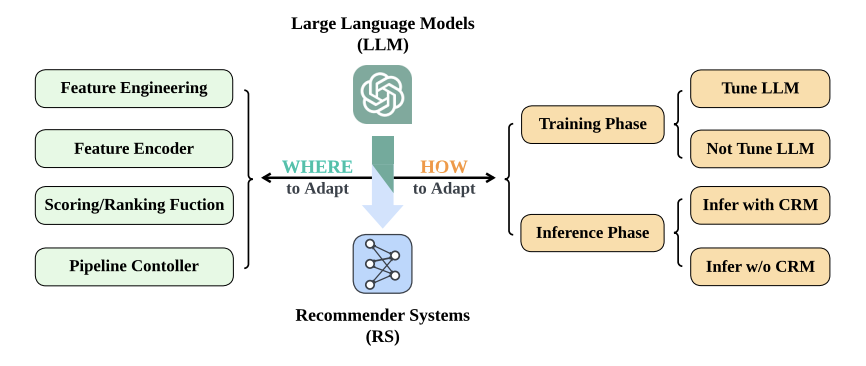
Integration of LLMs in Recommender Systems
Recommender systems help users explore unfamiliar products and services by analyzing their preferences and past choices. Integrating LLMs into these systems has gained momentum, enhancing recommendation quality and user experience. This trend underlines the broad application of LLMs in various natural language processing (NLP) tasks within the recommender system domain.
As recommender systems continue to advance, their efficacy hinges on the seamless integration of LLMs. This fusion doesn’t just unlock great potential but also presents many challenges set to redefine recommendation mechanisms.
Whether through approaches like zero-shot learning, few-shot learning, or fine-tuning methods, the utilization of generative LLMs holds the promise to revolutionize how recommender systems operate. As a result, leveraging this integration provides enhanced personalization and relevance, thus redefining user experiences.
Moreover, initiatives like ALLY, standing for Assisting LifeLong user journeY, demonstrate the potential of LLMs. This initiative is led by industry experts like Konstantina Christakopoulou. ALLY is aimed at building the next-gen of “companion” recommender systems. These systems assist users throughout goals they might want to accomplish, tasks they want to pursue, or points of their journey when they simply want to explore or entertain. To hear more on this topic, tune in to Konstantina’s talk on ALLY: large language models for companion recommenders, at this year’s summit!
RuterGPT: Transport Model Based on Open Source LLM
In enterprise digitalization, the journey towards using LLMs like ChatGPT has shed light on new possibilities. With the development of concrete enterprise applications, valuable learnings have emerged; from grappling with tech stacks and software architectures to overcoming challenges, the experience has been enlightening.
In the same way, real-world implementations of LLMs, such as RuterGPT, exemplify their practical utility. Led by industry experts like Umair M. Imam, these initiatives showcase the potential of LLMs in diverse applications, from transportation models to AI-driven entrepreneurship. More on this topic, you can hear from Umair‘s talk on RuterGPT: transport model based on open source LLM, at the summit.
LLMs on a Single Graphic Processing Unit (GPU)
Amidst all these advancements, the practical deployment of LLMs remains a focal point. Highlighting the importance of optimization strategies, particularly on resource-constrained platforms, is crucial to ensuring the efficient utilization of LLMs within enterprise settings. For a deeper exploration of this subject, we invite you to tune into industry expert Aditya Jain’s talk at this year’s Data Innovation Summit! In his talk, Aditya will be sharing his insights on deploying LLMs on a single GPU (Graphic Processing Unit).
How to Run LLMs on a Single GPU. The rise of large language models such as GPT-4 and Gemini Ultra comes with increased costs associated with their training and deployment. “With training costs reaching $78 million for GPT-4 and $191 million for Gemini Ultra, the need for efficiency in LLM deployment is more critical than ever.” states Aditya Jain during his talk at the summit.

Large Language Model Operations (LLMOps) and Foundation Model Operations (FMOps)
What distinguishes LLMOps from FMOps? What ethical considerations are involved in fine-tuning language models? How might the convergence of LLMOps and FMOps reshape both language AI and financial analysis?
Large Language Model Operations (LLMOps) and Foundation Model Operations (FMOps) specialize in managing distinct types of models:
- LLMOps concentrates on large-scale language models like GPT, fine-tuning them for specific purposes, ensuring their efficiency, and addressing ethical considerations. LLMOps emphasizes natural language understanding and generation.
- In contrast, FMOps encompasses the operational capabilities essential for efficiently managing data, aligning, deploying, optimizing, and monitoring foundation models within the framework of an AI system.
In addition, at the Machine Learning & Generative AI Stage at this year’s Data Innovation Summit, speaker Sanchit Juneja promises in-depth insights into the intersection of LLMOps and FMOps. This intersection holds the key to unlocking efficiency in the deployment and management of LLMs, offering insights for practitioners and enthusiasts alike.
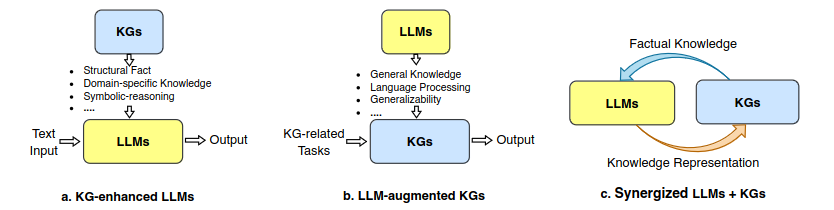
The Intersection of LLMs and Knowledge Graphs
Similarly, the intersection of LLMs and knowledge graphs offers new avenues for extracting insights and guiding future research endeavors. By leveraging LLMs in conjunction with knowledge graphs, organizations can unlock valuable insights from vast repositories of textual data.
To delve deeper into this topic, industry expert Swati Anand will be talking more about knowledge graphs and LLMs at the Data Innovation Summit 2024. This talk will reveal the potential of this integration, offering perspectives on leveraging language models and knowledge graphs for enhanced understanding and discovery.
Furthermore, the union of LLMs and knowledge graphs has the potential to enhance knowledge representation. Large language models are amazing, but also are black-box models that often fail to capture and accurately represent factual knowledge. Knowledge graphs, by contrast, are structural knowledge models that explicitly represent knowledge and indeed allow us to detect implicit relationships.
News Classification with LLMs: Building Reliable Evaluation Datasets
In data engineering and practice, leveraging LLMs for news classification is a promising avenue. However, ensuring the efficacy of such models requires meticulous attention to building reliable evaluation datasets.
By curating datasets that encompass diverse news sources, topics, and sentiments, data practitioners can enhance the robustness and accuracy of LLM-based classification systems, facilitating more reliable decision-making processes in information analysis and dissemination. More on this topic from industry expert Trine Engelund, who will be talking more on news classification using LLMs and building robust evaluation datasets, at the Data Innovation Summit 2024.
In Conclusion
The journey towards unlocking the full potential of LLMs spans diverse domains and disciplines. This interdisciplinary exploration yields valuable insights, propelling us closer to transformative advancements.
Exciting possibilities lie ahead as we witness just the beginning of the revolution in large language models.
For the newest insights in the world of data and AI, subscribe to Hyperight Premium. Stay ahead of the curve with exclusive content that will deepen your understanding of the evolving data landscape!











