
Large language models – advanced artificial intelligence systems trained on vast amounts of data to understand and generate human-like text.
How exactly do these models carry out such functions?
In today’s modern age of sophisticated AI, the training of large language models (LLMs) is significant. It shapes the course of future communication, automation, and information processing.
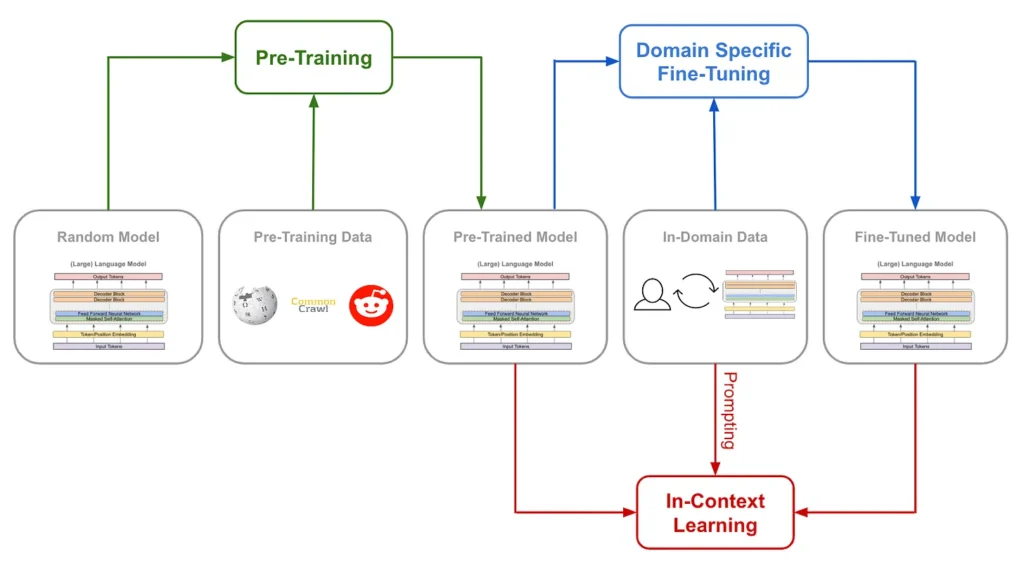
Today, the need to ensure not only the effectiveness but also the reliability and fairness of large language models (LLMs), is non-negotiable. Their performance hinges on precise pre-training, absorbing vast data to understand human language. For this reason, rigorous examination and improvement are essential to mitigate biases.
Beyond Bias: Building Trustworthy LLMs through Rigorous Training Regimes
Rigorous training of large language models (LLMs) is essential for sharpening their language understanding, contextual awareness, and task versatility.
A well-designed training regime, including diverse datasets and optimized parameters, enhances LLMs’ ability to generate coherent and contextually relevant text. Investing in effective training fosters innovation, and adaptability, and avoids biases, ensuring reliable outcomes. As a result, this enhances linguistic proficiency and drives AI advancement across applications.
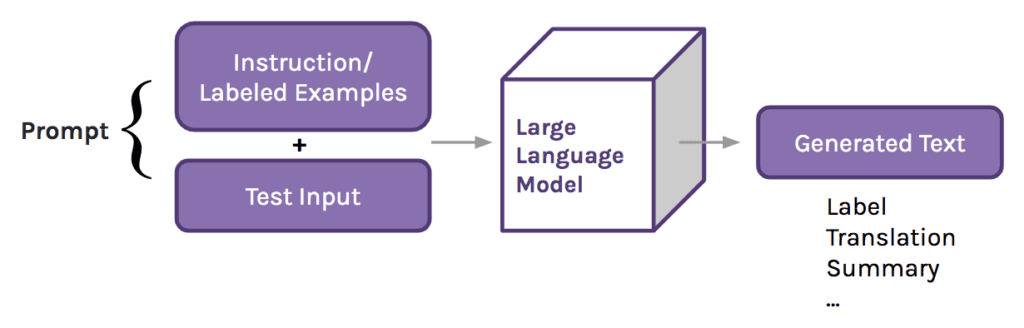
LLM training consists of complex stages. Data preparation is crucial, in curating vast datasets. Architectures, often transformer-based, need careful parameter consideration. Advanced methods like data parallelism, model parallelism, mixed precision training, and GPU-to-CPU offloading enhance efficiency within resource and memory constraints.
Effectiveness of LLMs: 4 Pillars to Effective Training of Large Language Models
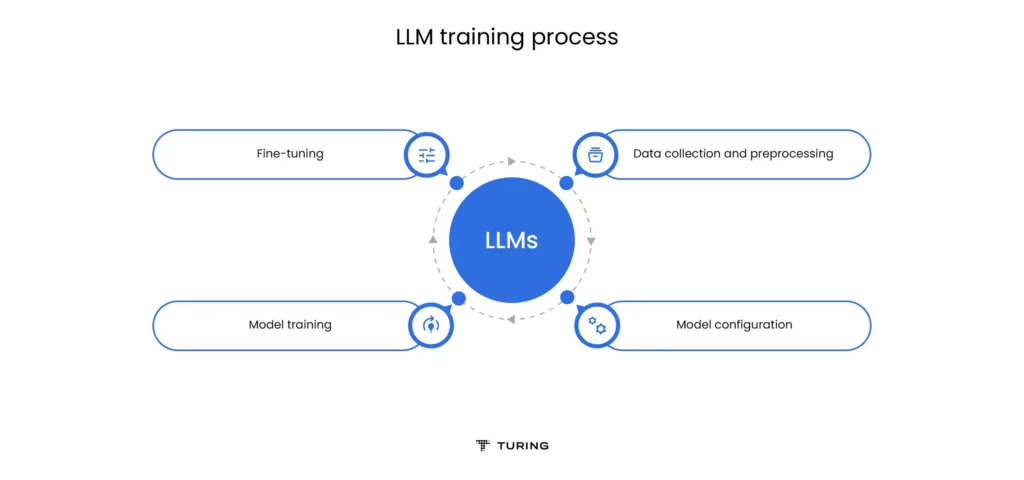
1. Data Curation and Pre-processing
It’s no secret that large language models (LLMs) have revolutionized various fields, from text generation to machine translation. However, their success hinges on high-quality, well-preprocessed data.
Imagine a LLM trained on raw customer reviews containing typos, emojis, and informal language. It might struggle to understand the sentiment and recommend relevant products. Preprocessing by removing noise, standardizing formatting, and correcting typos can significantly improve accuracy and customer satisfaction.
A LLM analyzing unfiltered social media posts filled with sarcasm, slang, and hate speech can be easily misled. Preprocessing by identifying and handling sarcasm, filtering offensive language, and understanding context can lead to more nuanced and accurate sentiment analysis.
- Tokenization: This involves breaking down text into smaller units, such as words or sub-words, to help language models understand the structure of the language better. The appropriate tokenization method depends on factors like the language being processed and the specific task at hand.
- Handling out-of-vocabulary (OOV) words: Language models may encounter words that are not present in their training data. Techniques such as replacing these out-of-vocabulary words with synonyms or using subword information can help address this issue.
- Language-specific preprocessing: Different languages have unique characteristics and requirements for processing. For instance, some languages may require specific handling of diacritics (accents) or morphological variations of words. Tailoring the preprocessing steps to the target language is crucial.
2. Model Architecture and Hyperparameter Tuning
The architecture of a large language model is its skeleton, defining its capabilities and limitations. Selecting the right architecture is crucial for achieving optimal performance in real-world applications. Here’s a breakdown of key factors to consider, along with practical examples:
Understand your use case: content generation: LLMs like GPT-3 are excelling in generating creative text formats, from poems and code to scripts and musical pieces.
- Machine translation: Architectures like the Transformer, used in Google Translate, have revolutionized machine translation accuracy, breaking down language barriers for real-time communication.
- Question answering: LLMs trained on vast knowledge bases, like LaMDA by Google AI, can answer questions in an informative way, assisting with research and information retrieval.
Balance performance and efficiency: number of layers and hidden units: While more layers and units can improve performance on complex tasks, they also increase computational cost. For instance, Megatron-Turing NLG by NVIDIA, with its massive size, pushes the boundaries of language modeling capabilities, but requires significant resources.
Power of attention mechanisms: Attention mechanisms, like those used in the Transformer architecture, allow the model to focus on specific parts of the input sequence, leading to better understanding of context and relationships between words. This is crucial for tasks like question answering and summarization.
Positional encoding captures order: In the absence of word order information in raw text data, positional encoding techniques like sine and cosine functions inject information about the relative position of words within a sequence. This helps the model understand the context and relationships between words.
Hyperparameter tuning: fine-tuning touch: Hyperparameters like learning rate and batch size significantly impact model performance. Carefully tuning these parameters through experimentation is essential to squeeze the most out of your chosen architecture.
3. Training Strategy and Optimization
Imagine training a massive language model like ChatGPT or Google Bard. Standard methods can take weeks or even months!
To speed things up, these models use distributed training, splitting the work across multiple computers, like training multiple chefs in different kitchens. They also use gradient checkpointing, saving progress efficiently, similar to taking breaks while cooking but remembering the recipe’s steps. Finally, they leverage the knowledge of pre-trained models, like an experienced chef teaching me their techniques, through transfer learning and curriculum learning (gradually increasing difficulty), significantly reducing training time and resources. This allows the models to learn faster and become more effective language models.
4. Evaluation and Iteration
In machine learning and AI, setting up robust evaluation metrics and benchmarks is crucial in determining the model’s effectiveness and efficiency. Firstly, clear evaluation metrics provide a standardized framework for assessing a model’s performance across various tasks and datasets. This clarity not only enables consistent measurement but also fosters transparency and trust among stakeholders, enhancing confidence in the model’s capabilities.
Moreover, benchmarks serve as reference points that help practitioners contextualize their model’s performance within the broader landscape of existing solutions or industry standards. By benchmarking against established baselines or state-of-the-art approaches, teams can gauge advancements and identify areas for innovation. This emphasis on continuous improvement underscores the importance of benchmarks in guiding research and development efforts.
Regular evaluation, both during development and testing phases, is indispensable for assessing a model’s generalization capabilities and robustness. Validation on unseen data sources illuminates the model’s ability to generalize beyond the training set, guarding against overfitting and ensuring real-world applicability. Any performance degradation detected during evaluation prompts iterative refinement, driving the model towards greater heights of performance and efficiency through a feedback loop between evaluation results and the training process.
From Text to Transformation: The Power of Rigorous LLM Training
Training LLMs is crucial for advancing AI in communication, automation, and information processing. Rigorous training, involving diverse datasets and optimized parameters, hones LLMs’ language understanding and versatility, driving innovation. Effective training encompasses data curation, model architecture selection, strategic training strategies, and robust evaluation, enhancing LLM accuracy and fostering continuous AI improvement.
For the newest insights in the world of data and AI, subscribe to Hyperight Premium. Stay ahead of the curve with exclusive content that will deepen your understanding of the evolving data landscape.





