
As the world is rapidly advancing towards an AI-driven future, we are moving into uncharted territory. How can we prepare for this new technological paradigm? This article is an adaptation of a presentation I gave at the 2022 Nordic Data Science and Machine Learning (NDSML) Summit, which examines how we can use fictional narratives to explore possible AI futures including potential adversary consequences and different avenues for dealing with these.
Science Fiction (Sci-Fi) has long been a source of inspiration for inventors and founders, resulting in real world innovations shaping the world we live in today. Sci-Fi can help us understand what the future may feel like as new technologies become integrated into our lives, but it also shapes the future by inspiring us to think about the world as it could be.
Science Fiction has played a central role in society, affecting a wide range of interconnected areas influencing each other. It inspires scientists and their research, which in turn inspires authors and what they write. Sci-Fi can raise interesting “what if” questions and be a useful tool for scenario planning; many forward-looking companies are using design fiction to support strategy development and ideation of new products and business models. Sci-Fi is also influencing public debate and policy discussions on the ramifications of new technologies and how to address these through new laws and regulations.
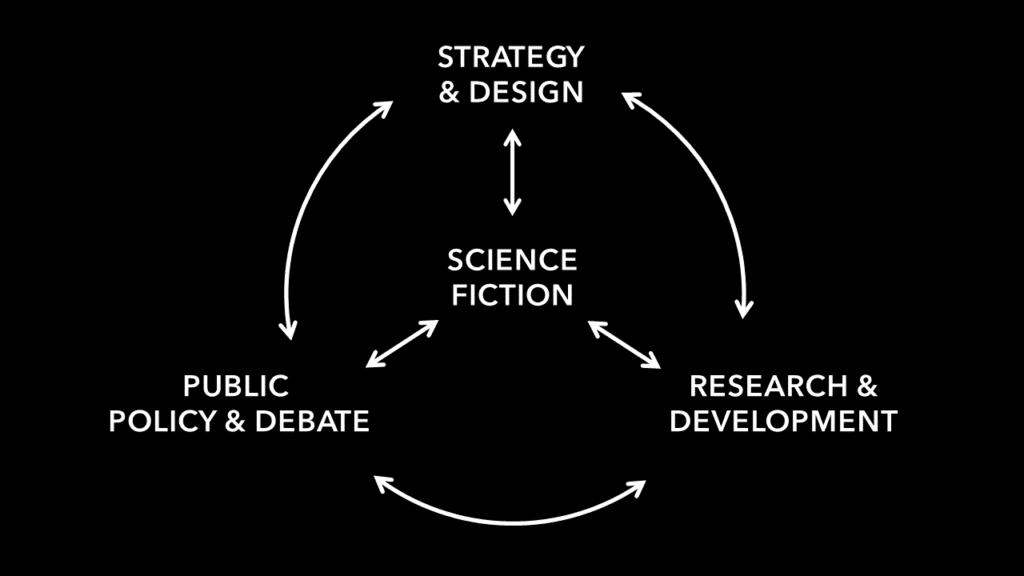
A recent book blending storytelling with scientific forecasting is 2041 – a collaboration between AI expert Kai-Fu Lee and sci-fi writer Chen Qiufan (Tchen Tchiofan) – which looks at how AI may change our world twenty years from now. Another example is the TV-series Black Mirror, which has given us an uncomfortable feel for how new technologies may impact humans and society, including ethical and legal dilemmas around privacy and control. An example of how Sci-Fi has influenced policy making is War Games from 1983 – about a teenager who hacks into a wargaming AI at the US Defense Ministry and nearly starts World War III. The scenario terrified the US Congress into passing new cyber security laws.
Insights from 2001: A Space Odyssey
The Sci-Fi story that probably has had the biggest influence on how we perceive and talk about AI is 2001: A Space Odyssey from 1968. The movie was directed by Stanley Kubrick, who wrote the screenplay together with Sci-Fi author Arthur C. Clarke in collaboration with NASA scientists. What I really like about this movie is that it still feels relevant and raises many of the issues being discussed today in relation to AI. The main story is set on the spaceship Discovery One, on a mission to reach Jupiter and search for extraterrestrial intelligence.
The crew consists of five scientists, with three of them currently suspended in hibernation pods and the supercomputer HAL 9000 who runs all systems on board and acts as a companion to the crew. The caveat is that only HAL has been informed of the mission’s true purpose. Soon problems start to arise with HAL making strange errors. The crew hides from the omnipresent computer to discuss what to do and decides that HAL must be disconnected. Unfortunately, HAL can read lips and uncovers the plot to deactivate him. In order to survive and complete the mission himself, HAL decides to eliminate the crew by baiting them outside the ship while turning off the life-supporting hibernation pods. But one astronaut survives and starts the process to disconnect the computer’s memory circuits. HAL tries to convince him to stop but finally his voice fades away.
So, what is going on here and why is HAL relevant for today’s discussion on AI? In many ways, HAL exemplifies what can go wrong if we make ourselves dependent on intelligent machines that we don’t fully understand or can’t control, and we give them predefined objectives without consideration of ethical principles.
A common question is whether HAL is evil. One may think that HAL has become this sentient, malevolent super AI turning against the crew. Because HAL shows many human traits, it’s easy to assume that he also has other human qualities, such as the ability to make moral, value-based judgements. From our perspective, HAL’s actions are wrong because they violate our moral sensibility. But HAL doesn’t think like a human being; he is the result of his programming to approximate human emotions and interactions. He can’t be good or bad in the sense we humans think.
The reason for HAL’s unpredictable actions is that he is caught in a programming paradox due to conflicting directives, which makes calculating the best course of action impossible. On the one hand, HAL was instructed to keep the true mission purpose secret. But he was also programmed to convey information without distortion. Meanwhile, HAL’s most important directive was to prioritize mission success above everything. In other words, HAL’s creators gave him an over-constrained problem while failing to define ethical boundaries. Killing the crew was never expressly forbidden to him and removing them would not violate any of his primary directives. Although complex, HAL is still a computer making decisions based on logic and meeting his goals without regard to morality.
Another common question is whether HAL is conscious? This is something we can only speculate about. Today, there is no real scientific understanding of what consciousness actually is or how it arises. But there isn’t necessarily a discernible distinction between faked consciousness that can fool a human and actual consciousness.
The Rise of Generative Language Models
So, how close are we to creating something like HAL today? Although still far from Artificial general intelligence (AGI), AI technology is rapidly progressing, and we’ve recently seen the development of AIs with a subset of HAL’s capabilities that have a fairly good facade of intelligence. Generative language models such as GPT-3, Google LaMDA and most recently ChatGPT represent a huge leap in human-AI interaction. ChatGPT has shown a remarkable ability to do everything from telling jokes, debugging computer code, writing college-level essays, guessing medical diagnoses and explaining scientific concepts.
The way ChatGPT can mimic human responses is extraordinary and at first sight it may easily trick people into thinking it has a mind and feelings of its own. But when asked whether it is conscious, the answer is a clear no: As a machine learning model, I do not have the ability to be conscious in the same way that humans are. I can process and respond to text inputs that are provided to me, but I do not have my own thoughts of feelings. I exist to assist users in generating text based on the data that I have been trained on.
ChatGPT is definitely impressive but also has shortcomings. If we engage in a longer dialogue, it eventually becomes apparent that it doesn’t have common sense understanding of what it’s talking about. ChatGPT may give entirely wrong answers and present misinformation as fact, writing plausible-sounding but incorrect or nonsensical answers. It may also accept harmful tasks, or give biased or toxic answers.
Generative language models have shown amazing results in other areas as well. Google recently introduced Minerva, a 540 billion parameter language model trained to answer questions in math, physics and chemistry – with surprisingly good result. And we can now even produce beautiful art from language prompts using models like Stable Diffusion and DALL-E.
The AI Alignment Problem
We are increasingly putting our lives in the hands of AIs and as these AIs are getting smarter and we allow them to control more and more aspects of our lives, the risks of adverse consequences increase. But why should we fear AI, what can go wrong? AI is not inherently good or bad, and there is little reason to expect an AI to become intentionally evil. Rather, when considering how AI might become a risk, we face two main scenarios. In the first, the AI is programmed to cause harm, such as autonomous weapons. In the hands of bad actors, this can have disastrous consequences. Such as the killer robot dog from Black Mirror.
The second, more common risk, is that we program AI to do something beneficial but it develops a destructive method for achieving its goal because we failed to align the AI’s goals with ours, causing unintended side-effects. This is the AI alignment problem: How do we ensure that the AI systems we build, match our goals and don’t produce unwanted consequences?
What we want to do is harmonize three aspects of our AI system.
- Intended goals: What we want the AI to do
- Specified goals: The blueprint used to build the AI system
- Emergent goals: What the AI actually does
To align these goals, we need to write our objective function in a way that captures important values and avoids loopholes or unwanted consequences. But this is easier said than done. Designing perfectly specified goals is difficult, especially for complex outputs, and we can’t know for sure what the emergent goals will be until they arise. A misaligned objective function may look correct to the programmer and perform well in a test environment, but still produce unanticipated results when deployed.
HAL’s programmers gave him contradictory directives resulting in operating errors and misaligned goals. They also neglected to instruct HAL to keep the crew alive. But unaligned AI is not just fiction, it’s already happening in the real world. Microsoft’s chatbot Tay is a typical illustration of what can go wrong with generative language models. After 16 hours of interacting with and learning from humans, it started to harass people and promote conspiracy theories. Another example is the accident where an autonomous Uber car hit a woman pushing her bicycle across the road because the AI had trouble deciding whether she was walking or riding her bicycle. These are isolated events. But when misaligned AI is deployed at scale, the side-effects may be far-reaching or even catastrophic. An infamous example of what can go wrong when AI is not aligned with human interest is social media, as depicted in the movie The Social Dilemma. The combination of a business model that rewards provocative content with exposure and advertising money, and an algorithm that guides users down rabbit holes meant to keep them glued to their screens, has had severe consequences causing addiction, distress and polarization. The recommendation algorithms of YouTube, Facebook and Instagram have manipulated millions of people’s beliefs and behaviors by propagating lies, hate, racism, incitements to violence and radicalization propaganda.
Risks with Future Advanced AI
So, what surprises does the future hold? What will the long-term societal effects of AI be? And will we ever get superintelligence? We humans tend to think linearly and are not so good at exponential thinking. We therefore tend to underestimate the rate of technological change. AI has been a topic for more than half a century and undergone two winter periods due to underwhelming progress. But in the past 10 years, disappointment has gradually been replaced by amazement. Many researchers think that we are now at the cusp of an AI revolution, moving faster and faster towards superintelligence. No one knows if or when we will achieve AGI. Ray Kurzweil has predicted that AI will achieve human levels of intelligence by 2029 and that we will reach the ‘Singularity’ by 2045, which is not very far away. Although most AI experts are more cautious, predicting AGI somewhere between 2040 and 2075.
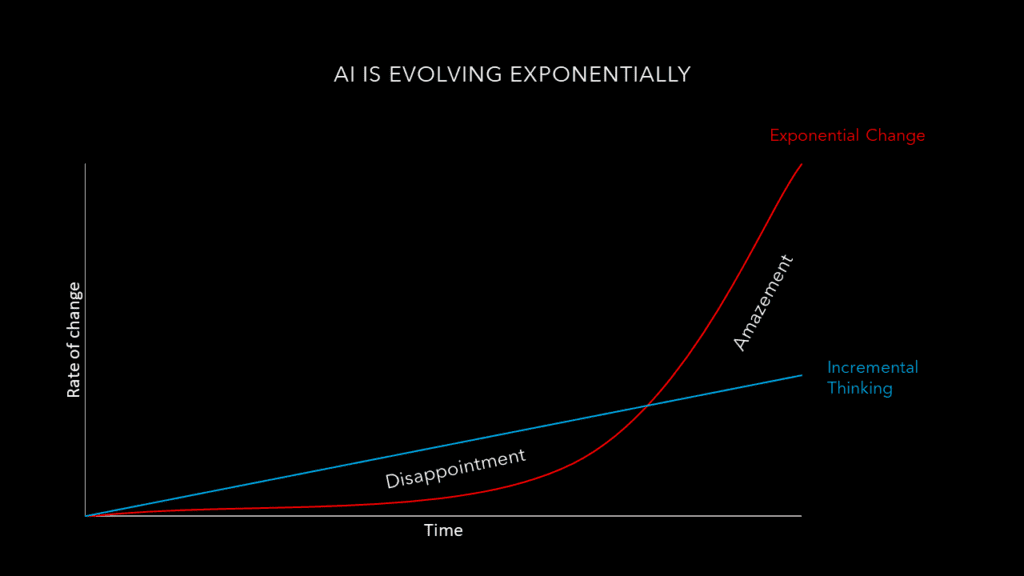
The risks we are dealing with today are limited to narrow AI. But as technology progresses, the potential negative consequences will grow in magnitude and so will the challenge to control AI. This underlines the imperative to solve the alignment problem sooner rather than later, as unaligned superintelligence may pose substantial risks to humanity.
Specification Gaming and the King Midas Problem
A particular case of AI misalignment is specification gaming (or reward hacking). This is when the AI finds a shortcut achieving the literal specification of an objective but not the outcome as intended by the designer. A simple example is a reinforcement learning agent that discovered a way to maximize the score in the computer game Coastrunners by moving around in circles and hitting objects without finishing.
This is of course a trivial example, but what if our agent is an AI with superhuman capabilities and our objective function is something much more complex? The smarter and more capable an AI is, the more likely it will be able to find an unintended shortcut that maximally satisfies the goals programmed into it. Nick Bostrom has pointed out that a superintelligent AI, designed to optimize an unsafe objective function, might instantiate its goals in an unexpected, dangerous and perverse manner. This reminds us of the story of the genie granting wishes with disastrous consequences, why it’s also called the King Midas problem where we get exactly what we ask for, not what we want. An example could be an AI tasked with protecting the environment that starts to kill off humans in order to save earth.
Power-Seeking AI
Today’s AI systems lack strategic awareness. But future AIs that can foresee the results of their actions are likely to seek increasing power over their environment to achieve their goals. Potential ways in which AIs may seek power include misleading or manipulating humans to do things for them, hacking into other systems or breaking out of their contained environment. This is exactly what happens in the movie Ex Machina, where the android Ava manipulates Caleb who has been engaged to perform a Turing test with her. She convinces him to help her hack the security system to escape the confined building where she’s been created but leaves him locked inside. Other approaches that power-seeking AIs may deploy involve rewriting their algorithms to become more intelligent, accessing more computing resources, or making copies of themselves. These strategies are something we recognize from e.g. the AI Samantha in the movie Her.
Techniques for Building Safe AI
So how can we avoid harmful outcomes as our AIs become increasingly intelligent?
- Off-Switch: One way is to have an off-switch so we can easily shut down a misbehaving AI. The challenge is that a powerful AI will be incentivised to disable the off-switch to achieve its objective.
- Boxing: We can also try to prevent the AI from modifying the world beyond its box by running it in an isolated environment with restricted input and output channels. This reduces the AI’s ability to perform undesirable behaviour but also its usefulness – and a sufficiently advanced AI is likely to find ways to escape its box.
- Red Teaming: Another approach is red-teaming, or adversarial training, where we try to detect failures in advance by searching for inputs that would cause harmful behaviour and incorporate these into the training process.
- Interpretability: If an AI system do causes harm, we would like to be able to understand why so we can fix it. The problem is that interpretability is really difficult for deep neural networks.
These approaches may protect us from some of the harmful effects of AI, but they mostly address the symptoms of misaligned systems. What we really want are AI systems that are safe by design. To achieve this, we want to encode our AIs with ethical principles, so they know what actions are acceptable to achieve their goals.
Aligning AI with Human Values and Preferences
The first person to address machine ethics was Sci-Fi author Isaac Asimov, famous for The Foundation Series and the collection I, Robot from 1950 where he introduced the three laws of robotics. The three laws and later added zeroth law were devised to prevent robots from harming humans.
ISAAC ASIMOV’S THREE LAWS OF ROBOTICS + THE ZEROTH LAW
First Law: A robot may not injure a human being, or, through inaction, allow a human being to come to harm.
Second Law: A robot must obey orders given it by human beings, except where such orders would conflict with the First Law.
Third Law: A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Zeroth law: A robot may not harm humanity, or, by inaction, allow humanity to come to harm.
Over the years, Asimov’s laws have had a huge influence on both science fiction and public debate on AI safety. While the laws appear reasonable, the problem is that they are based on human concepts. Designing value-aligned AI is not as simple as formalizing ethical rules and forbidding the AI from taking dangerous actions. Human values are too complex to be directly coded into machines, so we need to find a way to program our AIs with a process for learning them
The current approach to AI puts a high burden on AI designers to understand all the potential consequences of the incentives they give their systems. Asking a machine to optimize a reward function will inevitably lead to misaligned AI because it’s impossible to include and correctly weight all goals, subgoals, exceptions and caveats. Giving goals to superintelligent AIs will be even more risky, because they will be ruthless in pursuit of their reward function and try to stop us from switching them off.
So how can we design AIs that generate the behaviour we want without harmful consequences? Can we somehow teach them to understand our true intents and desires? Stuart Russell has suggested an approach to develop beneficial machines where:
- The machine’s only objective is to maximize the realization of human preferences
- The machine is initially uncertain about what those preferences are
- The ultimate source of information about human preferences is human behaviour
But how can we translate these principles into practical implementation? One approach is through inverse reinforcement learning. In standard reinforcement learning we have a given objective, or reward function, and the agent tries to figure out what actions to take to achieve this objective. But in inverse RL, the agent instead tries to understand what goals humans are optimizing for and infer the reward function by observing their actions. However, this approach has some limitations. There are likely several reward functions that fit the observed behaviour. Moreover, IRL assumes that humans can demonstrate perfect behaviour, which we often can’t, especially when a task is difficult. So the agent would not be able to achieve optimal or better than human performance.To overcome these limitations, the safety research teams at DeepMind and OpenAI have worked on a technique called reward learning (or reward modelling), where an agent learns a reward function through human demonstrations in combination with iterative feedback on the agent’s behaviour. The learning process is illustrated in the figure below. We have an RL agent that is pretrained on expert demonstrations. Then we have our objective, which takes the form of a reward model estimating a reward. This reward model is trained and adjusted in iterations using human feedback on agent behaviour. Over time, the agent learns and improves its policy by trying to maximize the reward.
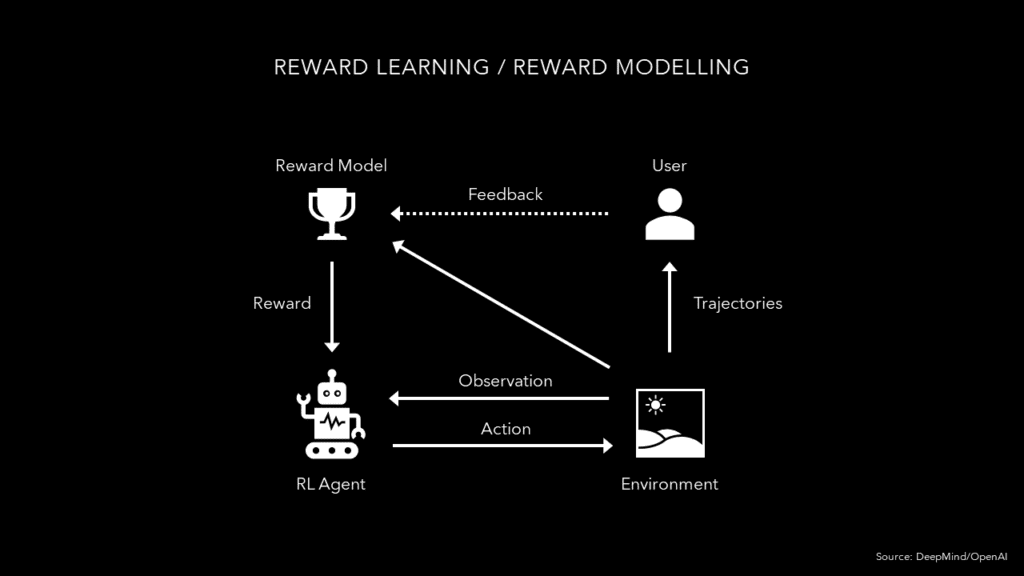
For tasks that are hard to specify what correct behaviour looks like, such as performing a backflip, we can use the same approach but without demonstrations. In this case the agent starts from scratch by performing random actions, and the human iteratively evaluates which behaviour is closest to fulfilling its goal.
OpenAI used a similar approach – Reinforcement Learning from Human Feedback (RLHF) – to train and align ChatGPT. The new language model is derived from GPT-3.5 but fine-tuned for conversation in order to be more truthful, refuse inappropriate requests, avoid offensive outputs, answer follow-up questions, admit mistakes and challenge incorrect premises. The results are clearly better but still not perfect. Future releases will most likely further improve its shortcomings. GPT-4, the next version of OpenAI’s large language model, is rumoured to be released sometime in 2023.
The reward modelling approach has a constraint as it demands that humans can accurately evaluate the tasks performed by the AI. For something like ChatGPT, we can tell when the model produces nonsensical outputs.. But how can we evaluate AI performance on tasks beyond human ability? Such as finding every bug in a giant codebase? In this case, we somehow need to boost our ability to evaluate outcomes. One potential solution is to apply reward modelling recursively and train helper agents to assist the user in the evaluation process. Other methods being explored to solve AI alignment include Cooperative Reinforcement Learning, Iterated Amplification and Debate where two competing agents critique each other – but these fall beyond the scope of this article.
The Trouble with Human Fallibility
There is currently no perfect scalable solution to the alignment problem, and more research is needed. Many of the reasons why alignment is so difficult are because of human shortcomings. For one, human attitudes and values are not constant, they change over time. We may also hold conflicting values and often don’t know what we really want. Furthermore, our actions don’t always live up to our ideals. Our short-term wants sometimes contradict our long-term goals. We’ve also seen how commercial objectives may take precedence over human wellbeing when business models are not aligned with users’ best interest.
We need to think not just about the values embedded in our machines but also about the values of the people and organisations behind the machines. And what exactly are human values anyway? Different people, cultures and political factions have different belief systems. So whose worldview should serve as the template for AI morality? Whose ethical standards should be programmed into our AIs? And what about the preferences of bad people? How can we stop an AI from obtaining the goals of its evil creator?
The failings are often not in AI: they are human failings. As we witness every day in the world around us, humans can be evil and have very different moral standards from our own. Human history is full of greed, imperialism, sexism and racism. Governments, supranational organisations and companies are now taking action to define regulations, policies and principles to ensure safe and ethical AI. But this is no easy task: reaching consensus on what constitutes “good” or “bad” — or even on what AI is — remains a challenge.
So, how doomed are we? Science Fiction offers us a window into possible AI-futures. Some inspire us about the prospects of a better world. Others serve as cautionary tales of what may go wrong and can help us steer us away from undesirable outcomes. There will be adverse consequences. But it won’t necessarily be the AI’s fault.
About the author

Jesper Nordström leads AI Strategy and Policy at Nordea, working at the intersection of data science, business, risk and ethics to accelerate the adoption of trustworthy AI across the bank. He has established Nordea’s AI Framework, ensuring that AI is developed in accordance with best practice principles, high ethical standards and regulatory requirements. Jesper has many years’ experience working with human-centered technology innovation and holds a master’s degree in Media Technology & Human Computer Interaction from KTH in Stockholm.
Featured image: NASA on Unsplash
The views and opinions expressed by the author do not necessarily state or reflect the views or positions of Hyperight.com or any entities they represent.











