Imagine AI that learns and adapts in real-time, seamlessly integrating vast knowledge for precise, context-aware responses. This is becoming reality with retrieval-augmented generation (RAG)!
Retrieval-augmented generation integrates search functions with generative models, boosting response accuracy and contextual understanding with external data. Queries in RAG trigger detailed retrieval from datasets, empowering models to exceed traditional limits.
The power of retrieval-augmented generation systems lies in precise retrieval execution. By curating and ranking documents strategically, organizations not only enhance response quality but also build robust RAG architectures, and elevate conversational standards.
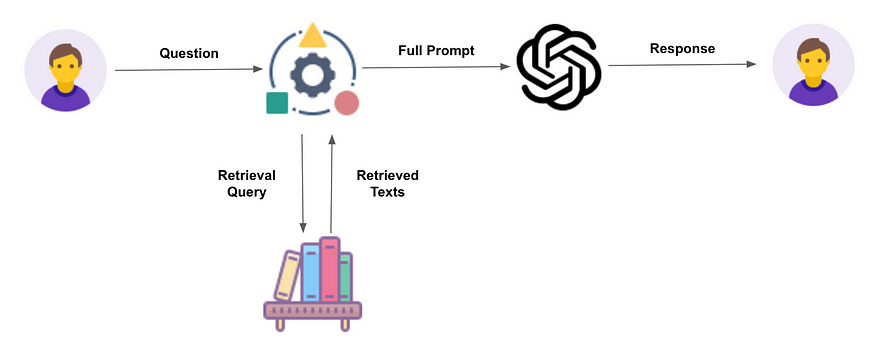
Approaches to Enhancing RAG Beyond LLM Capabilities
“2024 will be even more about RAG than 2023. Going beyond the simplistic one-size-fits-all solutions to bespoke use case specific solutions, where the smartness of the retriever solution will play a huge role, not just the LLM.” as stated by Johan Harvard in an article on gen AI trends redefining enterprises in 2024.
1. Query Rewriting. Deploying retrieval-augmented generation (RAG) systems faces a challenge with the variability of user queries. Unlike simple factual questions, users frequently present complex inquiries that demand nuanced retrieval strategies. For example, queries such as “Where do dolphins live?” may appear straightforward but necessitate refined search techniques for precise results. This underscores the critical role of query rewriting in enhancing the effectiveness of RAG systems.
When faced with a user query, a language model (LLM) with query rewriting capabilities can craft a precise search query. Rather than a generic search for “dolphins,” the LLM generates a query tailored to extract specific details about dolphin habitats. This strategy boosts the relevance and accuracy of retrieved information. This in turn, enhances the effectiveness of the RAG process as a whole.
2. Multi-Query RAG for Comprehensive Information Retrieval. Complex queries, such as comparing a company’s financial results across different years, require an approach beyond single queries. In such cases, multi-query RAG becomes essential. By segmenting the original query into multiple sub-queries – such as retrieving financial data for each specified year – the system aggregates comprehensive insights. This iterative process ensures thorough access to all necessary information before generating a response. This showcases the adaptability and depth of retrieval-augmented generation (RAG) systems.
3. Advance RAG with Multi-Hop Retrieval. Multi-hop RAG excels in handling complex inquiries that span multiple sources. For example, querying electric vehicle (EV) production across major car manufacturers often involves sequential searches across various documents and databases. This capability allows the model to navigate and accumulate sufficient data through successive hops. This transforms the RAG system into a versatile tool beyond simple fact retrieval.
4. Integrate Tool Use into RAG Systems. The evolution of retrieval-augmented generation (RAG) systems goes beyond information retrieval. Integrating tools into the framework empowers LLMs to execute actions like interacting with APIs or performing calculations. Moreover, this expansion broadens RAG system functionality, positioning them to execute tasks based on retrieved knowledge. As RAG progresses, it will incorporate external tools as a standard feature, enhancing the utility and applicability of AI-driven solutions.
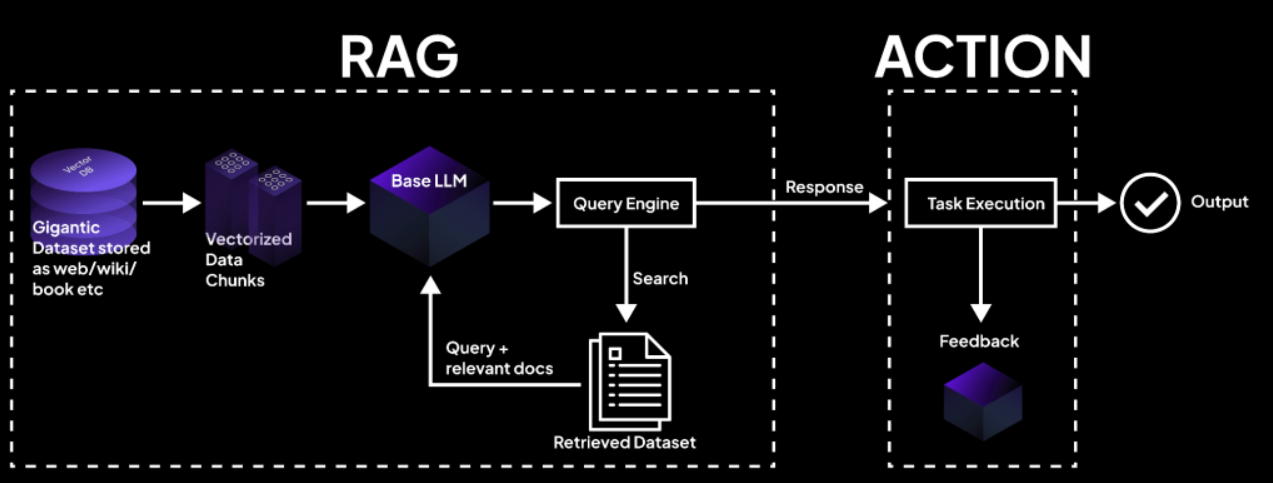
6 Ways for Humans to Optimize RAG Performance
1. Well-organized & Clearly Formatted Data
To optimize retrieval-augmented generation performance, one of the primary challenges lies in managing data that lacks structure or a clear format. When data isn’t formatted correctly, it becomes difficult to segment it into meaningful chunks. This lack of structure can hinder the RAG system’s ability to retrieve relevant information efficiently. Ensuring that data is well-organized and clearly formatted is essential for improving the system’s performance.
2. Presence of Contextual Metadata
Another crucial aspect is the presence of essential contextual metadata. Contextual cues are necessary to guide the chunking process effectively. Without these cues, organizations may arbitrarily define chunks This may lead to segments that are either too large and filled with irrelevant information or too small and lacking sufficient context. This imbalance can introduce noise into the retrieval process and decrease the accuracy of the generated responses. For this reason, incorporating detailed metadata and contextual information can greatly enhance the chunking and retrieval accuracy.
3. Data Quality
Data quality is also a significant factor affecting RAG systems. Outdated or conflicting data can misguide the system, resulting in responses based on invalid context. Establishing a robust quality assurance mechanism is vital to ensure that only accurate and up-to-date information enters the vector store. By involving subject matter experts (SMEs) to review and validate the content regularly, organizations can maintain a reliable knowledge base that supports effective RAG applications.
4. Granularity of Data Segmentation
The granularity of data segmentation is another area that requires careful attention. Simply chunking data based on character count or sentence breaks might not capture the semantic context effectively, leading to mismatches between user queries and retrieved content. Regular audits and updates of the data, along with implementing fallback mechanisms for human intervention when gaps are detected, can help maintain the comprehensiveness and relevance of the data.
5. Prompt Quality
Prompt quality plays a crucial role in the effectiveness of a RAG system. High-quality prompts that cover a wide range of real-world user behaviors are necessary for thorough end-to-end evaluation. Thus, SMEs with a deep understanding of the knowledge base and user needs should be involved in creating and refining these prompts to ensure they are robust and comprehensive.
Similarly, when prompts are rewritten to meet system expectations, human oversight is essential to ensure that they remain true to the user’s original intent, thereby preserving the system’s effectiveness.
6. Human Involvement
Finally, human involvement is essential in several other areas, such as improving the reranking mechanisms to prioritize the most relevant data chunks, maintaining consistency in response style and tone, and ensuring the specificity of responses aligns with user expectations. By continually refining retrieval algorithms, providing corrective feedback, and curating training datasets, humans can significantly enhance the overall performance and reliability of RAG systems.
Optimizing RAG Performance & Combating AI Hallucinations
Today, retrieval-augmented generation (RAG) systems are set to redefine AI integration, therefore addressing the reliability issues of large language models (LLMs). RAG enhances accuracy by integrating external knowledge sources and advanced techniques like query rewriting and multi-hop retrieval, improving AI’s contextual understanding.
Optimizing RAG performance demands not only meticulous data management and quality assurance but also human expertise. Well-organized data, enriched metadata, and high-quality prompts are essential. Human oversight ensures AI responses are relevant and minimizes inaccuracies.
By blending human ingenuity with cutting-edge AI, RAG not only sets new standards for conversational AI but also brings us closer to AI that learns and adapts in real-time.
For the newest insights in the world of data and AI, subscribe to Hyperight Premium. Stay ahead of the curve with exclusive content that will deepen your understanding of the evolving data landscape.










Add comment