
An emerging paradigm in AI may make the application of AI and Deep Learning in an enterprise much more accessible and feasible. That is the Foundation Models.
Hagay Lupesko, VP of Engineering at MosaicML (previously Director of Engineering at Meta AI), at this edition of the Data Innovation Summit, explained everything you need to know about Foundation Models. The starting point of his talk was the journey of Deep Learning over the past decade, through the success of the AlexNet model, the rapid progress and enormous value delivered, to the introduction of the relatively new concept on the path of Deep Learning and AI – the Foundation Models.
In this article, you can also read about the opportunities and challenges these models offer when applying AI in the enterprise. Let us guide you through this new trend in the AI field.
The Rise of Deep Learning
Many would agree that there has been a rapid and somewhat surprising rise in Deep Learning over the past decade. It is an incredible rise because just a decade ago, most professionals in the AI field considered Deep Learning to be less relevant because of the challenges of scale and learning instability.
“If you look at the “Deep Learning” Search Popularity, you will see that roughly until 2012-2013, the term was not popular at all, and since 2013 there was a huge uptick that peaked in 2019 and stayed fairly popular ever since. In 2012, AlexNet, Deep Learning Model for image understanding was published and made a huge breakthrough in terms of being able to understand images.”, said Lupesko.
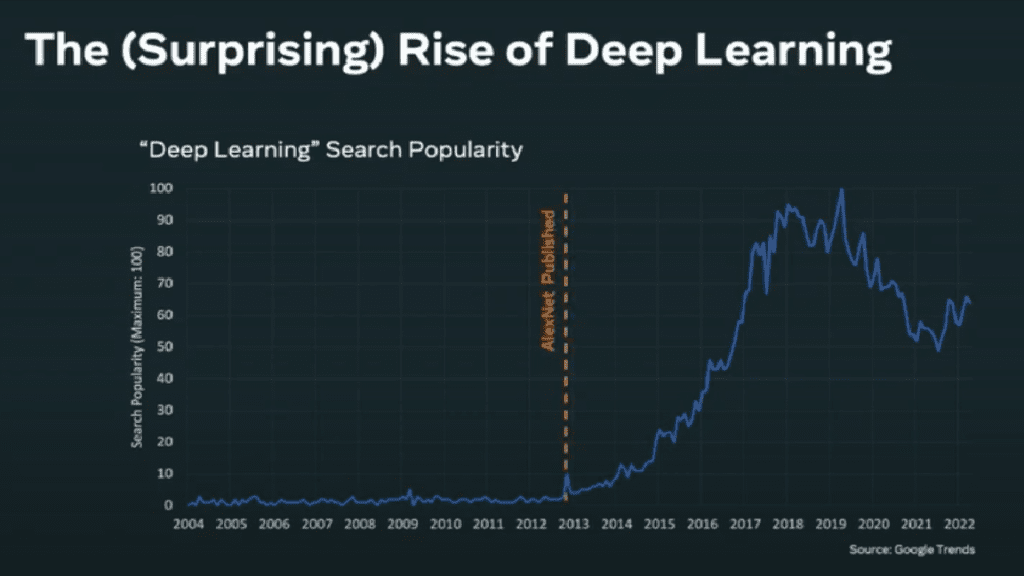
A few key factors enabled the huge success of the AlexNet, and even winning the 2012 ImageNet challenge. It was the first Deep Learning model that won that competition, and from 2012 onwards, every winner of the ImageNet challenge was a Deep Learning model. What can be seen since then is that private investment in AI started uptaking significantly – from about 3 billion USD in 2013 to over 90 billion USD annually today and still growing. What are the factors that influenced this success, you might ask?
Factor 1: IMAGENET – It is an image dataset with 14 million labelled images and around 10 thousand classes of labelled data on those publicly available images, which made Deep Learning training possible with this data. These massive labelled datasets became available because everyone started using ‘the camera in their pockets’ – the smartphones, and because of the rapid rise of the Internet that made all of that content that people created and collected publicly available.
Factor 2: GPUs – They were designed originally to enable the 3D rendering of computer games. But the general-purpose APIs for GPUs became available. The AlexNet team programmed against these APIs and was able to train AlexNet on just two GPUs. Before, training Deep Learning models on CPUs was impractical because it would take too long.
Factor 3: Algorithms – Neural networks are the backbone of Deep Learning algorithms, and terms such as layer normalization, drop out, and real activation are taken for granted today when Deep Learning models are built. But at the time, they were novel, and the AlexNet team used them all together in building and training AlexNet.
Many researchers made essential contributions to the emergence of Deep Learning, among whom Yann LeCun, Yoshua Bengio and Geoffrey Hinton. In 2019 they were recognized with the Turing Award, the highest recognition for computer science researchers. Their contributions and the application of Deep Learning made it possible today for Deep Learning to be everywhere and empower day-to-day lives in lots of different ways.
“If you look at super precise personalization algorithms that are running on social media sites, on your favorite streaming service, for video, audio or e-commerce; if you look at the natural sound “know it all” voice assistance; and up to upcoming things like autonomous vehicles and drug discovery, all these thighs are made possible with Deep Learning.”, adds Lupesko.
Challenges of Applying Deep Learning in Enterprise
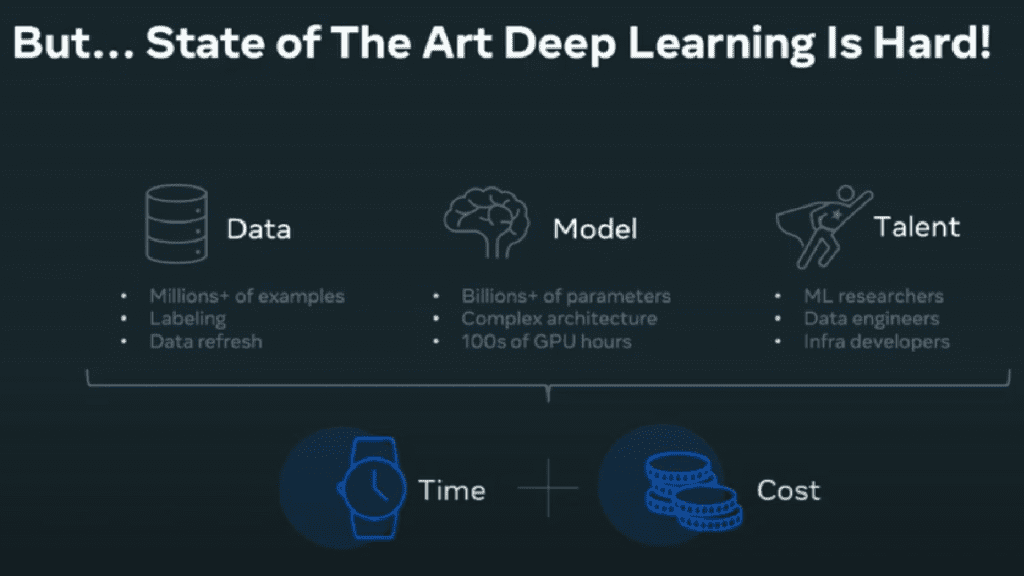
There are a few reasons that make applying Deep Learning in a system and an enterprise hard:
Data – Machine Learning and Deep Learning are mostly about data organizations have, both in quantity and quality. Deep Learning requires a lot of high-quality data for the model to train properly, work properly, deliver results, and avoid overfitting. The problem is that curating large scale datasets is expensive and time-consuming.
Model – Increasing model scale and model complexity is another reason. “If you look at AlexNet, it was the state-of-art model for image understanding nine years ago. It had about 16 million parameters, and it took about five days to train on two GPUs. If you fast forward today, nine years later, there is a new state-of-art image classification model called Florence, coming out of Microsoft. It has close to 1 billion parameters. If you look at the time and resources to train Florence, it requires about ten days on 512 NVIDIA A100 GPUs. State-of-art models today grow large, and it takes much more time, compute and money to train.”, explains Lupesko.
Talent – Advanced networks become very complex and developing. Training them and serving them requires a high level of expertise across many different domains, from data engineering through modelling up to system infrastructure. The population of software developers and ML developers doesn’t scale as fast as Deep Learning nowadays, so there is an ongoing struggle for talent and is pushing up both the cost to hire people and the time for hiring professionals.
All of the above makes advanced Deep Learning applications hard, time-consuming and costly.
The Next Chapter of Deep Learning – Foundation Models
In August 2021, a group of about 100 researchers from Stanford University published a technical report where they coined a new term – Foundation Models. That report came out of a new center of Stanford, the Center of Research of Foundation Models (CRFM) and it’s dedicated to just focusing on Foundation Models. That report is about 200 pages long, and it previews many aspects of Foundation Models across science, engineering, and society. Examples of such models are BERT (2018), GPT-3 (2020) as well as ViT (2021). According to Lupesko, these quotes tell the big story in short:
“AI is undergoing paradigm shift with the rise of models that are trained on broad data at scale and are adaptable to a wide range of downstream tasks.”
“We call these models foundation models to underscore their critically central yet incomplete character.”
The Foundation Models are the paradigm shift because of three main properties:
- Foundation Models are architected for high capacity – This enables these models to learn a general and high level of content representation such as text or images, and it is learnt from very massive datasets. To design such a high capacity model, architecture needs to leverage deep networks with tents and sometimes even hundreds of layers and leverage modelling techniques. The most recent one is Transformers. This results in a very high parameter count and computational complexity for training and inference.
- Foundation Models are pre-trained on broad data – Huge datasets typically scrapped from across the Internet are what empower the training of these models or, as it is called, pre-training. And while vision training data typically require labelling, the training of Language Models is usually done with self-supervision, so they don’t require labelling, which makes scaling datasets larger and relatively easier. “IMAGENET is a well-known vision dataset consisting of 14 million labelled images across 21 thousand classes. Common Crawl is a language dataset, and it’s built by regularly scraping the Internet and publishing the scraped data on an NWS so anyone can access it. In January 2022, Common Crawl is about 320 TiB of data used for training Foundation Models and is scraped across about 3 billion web pages. And there are many other datasets; some are closed and even larger. For example, Google has JFT-3B, an image dataset with over 3 billion labelled images.”, clarifies Lupesko.
- Foundation Models are adaptable for downstream tasks – This is where the value of Foundation Models comes from. Foundation Language Models can be adapted to handle many classical NLP tasks, such as question answering, translation or sentiment analysis. Models like BERT or GPT-3 show state-of-art results when adapted for these downstream tasks. “You take a Foundation Model that was trained for a general task, you adopt it, and you get state-of-art results across models, including models trained specifically for that downstream task. Similarly, for computer vision. The Foundation Models for computer vision can be adopted for image classification, object detection, and DeepFake detection. Like Language Models, Foundation Models for computer vision such as Florence published by Microsoft, show state-of-art results on many computer vision tasks”, explains Lupesko.
Adapting Foundation Models
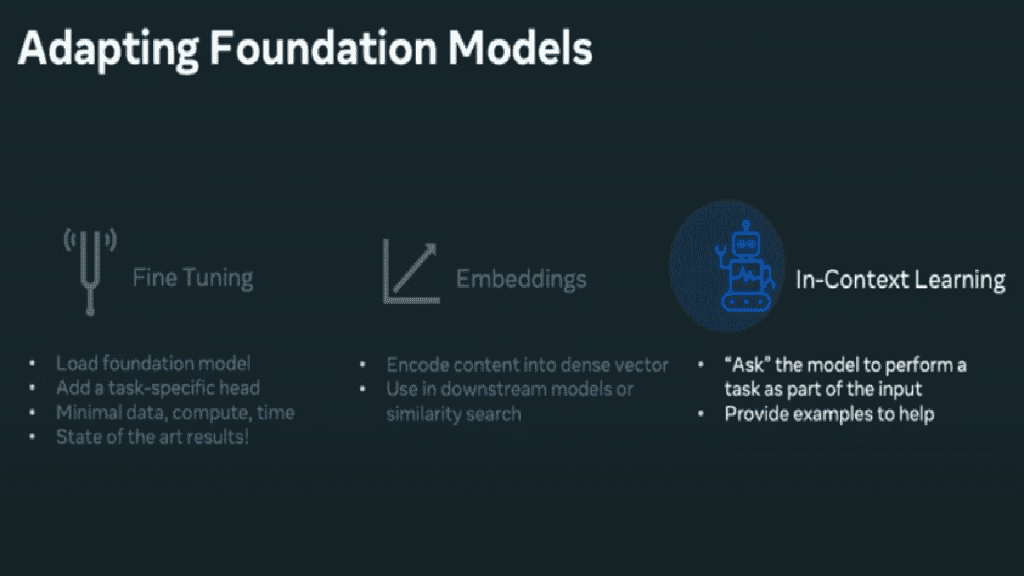
There are three main ways in which Foundation Models can be adopted:
Fine-tuning – To fine-tune a Foundation Model, a pre-trained model is loaded with its weights, a layer is added on the top, such as a linear layer for the task attend, and then the training of the newly created model starts with the task-specific datasets. Typically a backpropagate throughout the entire network is done to tune in the parameters and the weights for this specific task.
Embeddings – This is an extremely useful method and easy to apply. The Foundation Model is used as a feature and coder that takes in the content the model is trained on, such as a sentence in natural text or maybe an image or a video. The model then computes and embeds a dense vector out of this input. That dense vector is extremely useful because it is very information-rich and can be used in downstream ML models or as a vector for similarity search applications for things like retrieval.
In-Context learning – This is where the magic of state-of-art Deep Learning shines. Sometimes it is referred to an as zero-shot, single shot or few-shot learning. The model can learn the tasks without ever being explicitly trained for them. A task is provided as a natural text as part of the model input, and the model is told what the task to solve is, and the model can figure this out learnt just from that input and give the expected results. GPT-3 is a very well known mode for in-context learning. One of the things that makes this model stand out is its ability to handle in-context learning well.
Opportunities and Risks with Foundation Models
Some of the opportunities for enterprise when adopting Foundation Models are:
- Increase developer velocity – When an enterprise uses Foundation Model, there is no need to curate a large dataset, no need to train a large model, and no need to set up and maintain large scale infrastructure for training. It allows the ML team to focus on the business problem, experiment, and move quickly.
- Reduce infrastructure cost – With Foundation Models, organisations don’t need to build and train the backbone of the AI system. They save time and money on compute because GPUs are expensive.
- Tapping into state-of-the-art AI – The access to state-of-art AI used to be fairly reserved for the large AI labs and large tech companies. The playfield is levelled with the Foundation Models, and everyone can access state-of-art AI and apply it.
Some risks when adopting Foundation Models by enterprises are:
- Bias propagation – Any biases inherited into the Foundation Models will be propagating downstream for a specific application. That is why organizations should test the system for bias and be able to mitigate the bias.
- Increasing model scale – The complexity of Foundation Models is already very high and still growing. This may have implications on things like downstream the usage of the model for things like surveying when it is a large model. Organizations should be sure to consider this and manage that risk.
- Closed-source mode – The high cost of designing and training these models makes some companies keep the models closed-sourced, which is a new trend. GPT-3 is this model type, and its training code or parameters can not be seen or accessed.
Cost increase using cloud APIs – This means that relying on cloud base Foundation Models makes the cost for a downstream task go up with the usage of an AI downstream application. This is something organizations should consider, too.

Hagay Lupesko has these practical recommendations on how to leverage Foundation Models in a smart way:
- Seek to leverage Foundation Models where possible, especially if you want to fast explore AI-powered used cases.
- Understand and manage your cost factors, especially if the usage of the Foundation Model is going to scale up.
- Understand and manage the limitation on which the Foundation Model relies on, identify the bias and actively mitigate and address that bias.
- Follow the announcement coming out of the significant AI labs. These are the labs where a lot of the advancement of new Foundation Model models are being built and researched. If you stay tuned to that, it will allow you to move fast within your organization and leverage state of the art AI for your business use case.
To learn more, see Hagay Lupesko´s video presentation here: https://hyperight.com/foundation-models-the-future-of-enterprise-ai-hagay-lupesko-meta-ai/
Featured image credits: Fatos Bytyqi on Unsplash











