

The autonomous vehicle industry faces a peculiar paradox. To build safe self-driving cars, we need massive amounts of diverse driving data. But to collect that data safely, we need safe self-driving cars. It’s the ultimate chicken-and-egg problem, and it’s costing the industry billions while slowing down progress toward truly autonomous transportation.
Enter synthetic data, artificially generated information that mimics real-world scenarios without requiring a single mile driven on actual roads. What was once considered a poor substitute for “real” data has evolved into something far more valuable. A commodity that’s reshaping how we train machine learning models for autonomous vehicles.
The Real Cost of Real Data
Let me paint you a picture of traditional autonomous vehicle data collection. Companies deploy fleets of sensor-laden vehicles, each costing upwards of $200,000 in hardware alone. These cars drive millions of miles, capturing terabytes of data every single day. A single autonomous vehicle can generate up to 4TB of data per hour of driving.
But here’s the issue, most of that data is utterly monotonous. Hours of highway driving in perfect weather conditions. The same commute routes, repeatedly. What autonomous vehicles really need to learn from are edge cases, the pedestrian who suddenly steps off the curb, the motorcycle weaving through traffic, the debris in the road during a thunderstorm, the sun glare that blinds cameras at sunset.
These critical scenarios might represent less than 0.01% of real-world driving data. Finding them is like searching for needles in a haystack the size of a data center. And when you do find them, they’re often incomplete or maybe the sensors didn’t capture the right angle, or the lighting conditions obscured crucial details.
The economics simply don’t add up. Waymo has driven over 20 million autonomous miles on public roads. That’s impressive, but it’s still just a fraction of the diversity of scenarios a truly safe autonomous vehicle needs to handle. The National Highway Traffic Safety Administration estimates that proving autonomous vehicle safety through real-world driving alone would require hundreds of millions, if not billions, of miles.
Synthetic Data: From Supplement to Strategy
Synthetic data generation has matured from research curiosity into a strategic imperative. Modern simulation platforms can create photorealistic environments that are virtually indistinguishable from real footage or at least to a neural network.
But real power isn’t mimicking reality. It’s transcending it.
With synthetic data, engineers can conjure scenarios that would be dangerous, illegal, or simply impractical to capture in the real world. Want to see how your perception system handles a child running into the street? Create it synthetically, thousands of times, with variations in lighting, weather, vehicle speed, and pedestrian behavior. Need to test performance in a blizzard in Phoenix? No problem—synthetic snow falls on demand.
The controllability is transformative. Every variable becomes a parameter you can adjust time of day, weather conditions, traffic density, pedestrian behavior, road surface conditions, sensor configurations. This level of control enables systematic testing that’s impossible in the real world.
Consider this: Tesla’s Autopilot team uses simulation to generate scenarios based on real-world “disengagements”—moments when human drivers take over from the autonomous system. They can replay these scenarios with variations, testing different algorithmic responses without risking a single actual vehicle or passenger.
The Technical Evolution
Early synthetic data efforts suffered from what researchers call the “reality gap”. The difference between simulated and real-world data caused models to perform poorly when deployed on actual vehicles. Neural networks trained exclusively on synthetic data would fail spectacularly when confronted with real roads.
The industry has largely closed this gap through several technical breakthroughs:
Domain randomization introduces intentional variability in synthetic data such as textures, lighting, object appearances that force models to learn robust features rather than memorizing simulation artifacts. Instead of showing a model one perfect rendering of a car, you show thousands of variations with different colors, shapes, and lighting conditions.
Photorealistic rendering engines now leverage real-time ray tracing and physically based rendering to create visuals that match real-world camera behavior, including lens distortions, motion blur, and sensor noise. The latest generation of simulation platforms can model how different camera sensors respond to various lighting conditions with stunning accuracy.
Hybrid approaches combine synthetic and real data, using techniques like transfer learning and domain adaptation to bridge any remaining gaps. Companies typically use real-world data to validate and fine-tune models initially trained in synthetic data, getting the best of both worlds.
Procedural generation creates infinite variations of scenarios by algorithmically generating environments, traffic patterns, and weather conditions. This prevents models from memorizing specific scenarios and ensures broad generalization.
The Economics of Synthetic Data
Here’s where synthetic data becomes genuinely disruptive as a commodity. The marginal cost of generating additional synthetic data approaches zero. Once you’ve built the simulation infrastructure, creating your millionth scenario costs essentially the same as your first time.
Compare this to real-world data collection, where every additional mile driven incurs costs: vehicle wear and tear, fuel, safety drivers, data storage, and processing. The cost curve is inverted.
This economic reality is creating a new market. Companies like Applied Intuition, Cognata, and NVIDIA’s Omniverse are selling synthetic data generation platforms as a service. Others are creating libraries of pre-generated scenarios that can be licensed like stock photography.
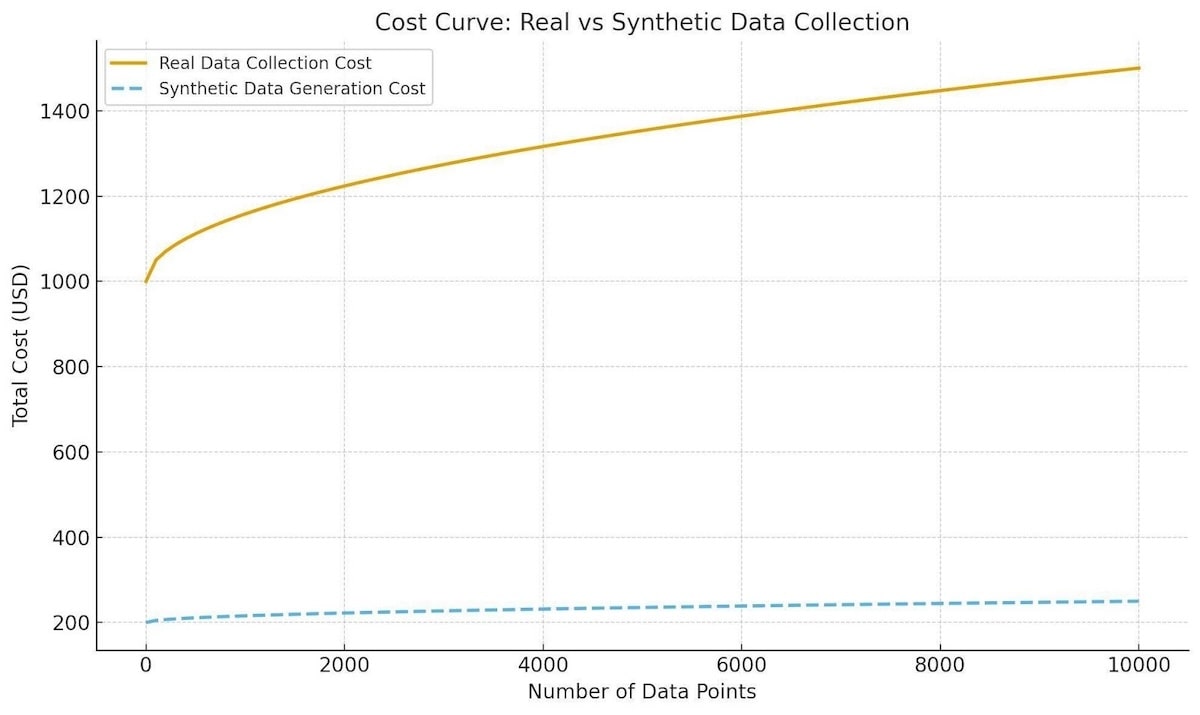
The data itself is becoming commoditized, but the expertise in generating useful synthetic data remains valuable. It’s not enough to create pretty simulation you need to understand which scenarios matter for safety, how to balance dataset composition, and how to validate that your synthetic data improves real-world performance.
Regulatory Implications
Regulators are taking notice. The challenge of proving autonomous vehicle safety through real-world testing alone has led agencies like the European Union Aviation Safety Agency and the UK’s Centre for Connected and Autonomous Vehicles to explore frameworks that incorporate simulation-based validation.
Synthetic data offers a path toward standardized testing. Instead of each company driving millions of miles and hoping they encounter relevant scenarios, regulators could define a standardized suite of synthetic scenarios that all autonomous systems must pass. This would be similar to the crash test standards in traditional automotive safety controlled, repeatable, and comprehensive.
However, this raises questions Who validates the synthetic scenarios? How do we ensure simulations accurately represent real-world physics and behavior? What’s the right balance between synthetic and real-world testing? These questions are actively being debated in regulatory circles worldwide.
Beyond Autonomous Vehicles
While autonomous vehicles represent the most visible application, synthetic data’s commodity status extends far beyond transportation. The techniques developed for AV training are being adapted for robotics, drone navigation, medical imaging, and industrial inspection systems.
The fundamental insight is universal when real-world data is expensive, dangerous, or rare, synthetic alternatives become not just viable but preferable. We’re seeing this pattern repeat across industries where machine learning meets physical reality.
In medical imaging, synthetic data helps train diagnostic AI without compromising patient privacy. In robotics, simulated environments teach robots to manipulate objects without expensive real-world trial and error. In aerospace, synthetic sensor data helps train systems for scenarios that would be prohibitively expensive or dangerous to test physically.
The Path Forward
The autonomous vehicle industry’s embrace of synthetic data represents a broader shift in how we think about training data for machine learning. Data is no longer just a byproduct of operations to be collected and stored it’s a designed product to be engineered and optimized.
This shift brings new challenges. As synthetic data becomes more sophisticated, ensuring it remains grounded in physical reality becomes crucial. The risk of “overfitting to simulation” creating systems that work perfectly in synthetic environments but fail in the real world remains real.
The solution lies in maintaining a tight feedback loop between synthetic and real-world data. Synthetic data accelerates development and enables comprehensive testing, but real-world validation remains essential. The most successful autonomous vehicle programs use synthetic data to explore the vast space of possible scenarios, then validate their systems’ responses with real-world testing.
As we look toward a future where autonomous vehicles become commonplace, synthetic data will likely be remembered as the catalyst that made it economically and practically feasible. By treating data as a commodity that can be manufactured on demand rather than being mined from reality, we’ve fundamentally changed the economics of machine learning development.
The question is no longer whether synthetic data will play a role in autonomous vehicle development, it’s how quickly the industry can scale its use while maintaining the safety and reliability that public trust demands. In this race toward autonomous transportation, synthetic data has emerged as both the fuel and the accelerator, proving that sometimes the best way to prepare for reality is to transcend it entirely.

About the Author
Nishant Arora is a Solutions Architect at Amazon Web Services (AWS), specializing in the Automotive and Manufacturing industries. His work focuses on applying Generative AI, Machine Learning, and Cloud technologies to enable large-scale digital transformation. He actively contributes to thought leadership and industry publications on AI-driven innovation and enterprise architecture.











