
The world of AI is a buzz with rumors and developments, from massive new models to exciting innovations. In this article, we explore some of the most talked-about topics, including the highly anticipated Reflection 70B and the mysterious “Strawberry” project!
We dive into an episode of the AI After Work Podcast, titled “Reflection 70B, Strawberry, and Other AI Rumors.” The episode features insights from Anders Arpteg, along with hosts Robert Luciani from The AI Framework and Jesper Fredriksson from Volvo Cars!
Join us as we explore the cutting-edge of AI model development and unlock the secrets behind today’s most exciting innovations.

Initial Discussion: The Reflection 70B Model
Meet Reflection 70B, a model that’s sparked controversy with bold claims of outperforming other AI models like LLaMA 3.1! This AIAW podcast episode begins with Jesper Fredriksson discussing his experiences with the Reflection 70B model. He highlights its initial promise and its limitations. Reflection 70B is a model that has generated significant buzz in the AI community. There are claims that it could surpass frontier models like GPT-4 and Claude in reasoning tasks.
However, users, including Fredriksson, found discrepancies between its claimed performance and real-world output. He notes that while the model followed a reasoning pattern, it often arrived at incorrect conclusions. This prompted skepticism about its capabilities.
Fredriksson and Luciani discuss the challenges with AI benchmarks. They explain that claims of high accuracy, particularly above 99%, often signal overfitting or faulty evaluations. They mention that early adopters quickly found issues with the model’s reproducibility, fueling a Twitter storm and accusations of fraud.
While the model’s developer, Matt Schumer, defended the Reflection 70B, saying it might be based on the wrong version of LLaMA (3.1 versus 3.0), the community remained doubtful. Luciani points out that the developer’s rapid shift to crisis management raised red flags. This was because the model did not meet the benchmarks it promised.
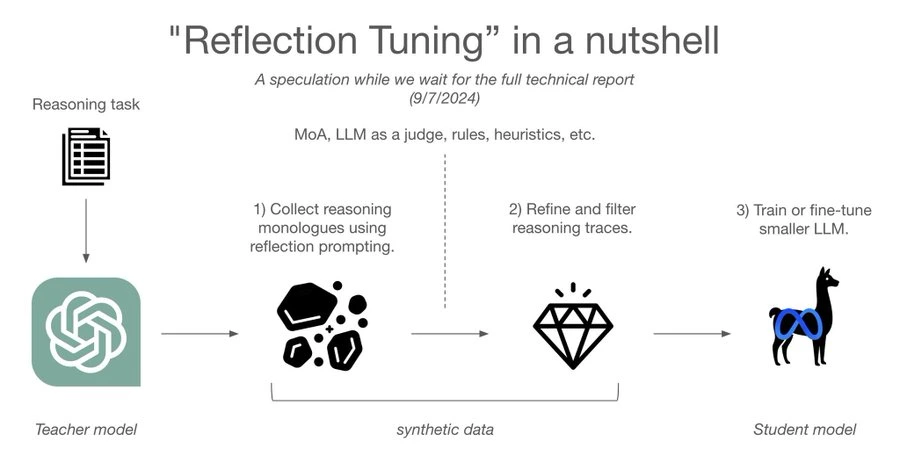
Reflection Tuning and Reasoning in Language Models
This AIAW podcast episode moves on to discuss the novel “reflection tuning” approach the Reflection 70B model attempted to introduce. This approach involves adding a layer of reflection after the model generates an initial response. When a problem is particularly difficult, the model flags its response as potentially wrong. It then prompts itself to reconsider or reflect, refining its output through multiple iterations.
This multi-step reasoning process mirrors human self-reflection and aims to allow models to reconsider their answers before committing to a final conclusion.
Fredriksson and Luciani view this as an exciting step towards more complex reasoning in language models. However, the implementation in Reflection 70B appeared flawed, with no concrete results to support the claims. The concept of self-reflection in AI models is still in its infancy, and though promising, it raises questions about whether current models can genuinely replicate human-like reflection.
The Controversy: Fraud or Misunderstanding?
As the episode delves deeper, hosts discuss the broader implications of the Reflection 70B controversy. Was the model developer intentionally deceitful, or did they simply misunderstand the limitations of their model?
Fredriksson believes that the developer may have been overambitious rather than fraudulent, as outright deception would quickly be uncovered in the highly scrutinized AI community. Nonetheless, the incident underscores the importance of transparency and rigorous testing in AI model development.
Luciani adds that this case highlights a broader issue in AI development: the gap between promising benchmarks and real-world performance. AI models can perform exceptionally well on specific tasks, particularly when trained on benchmarks, but may fail in more general applications. This discrepancy is often overlooked in the rush to claim breakthroughs, leading to overhyped models that disappoint when subjected to broader testing.
Cognitive Biases and AI
A recurring theme throughout the episode is the interplay between human cognitive biases and AI. Hosts discuss how AI models, trained on vast datasets, can replicate and even amplify human biases. They also touch on the limitations of human memory and reasoning compared to AI. While humans excel at quick learning and generalization, AI models are better at storing and recalling vast amounts of information. This difference highlights both the strengths and weaknesses of AI, with the hosts pondering whether AI will eventually surpass human cognitive capabilities.
Fredriksson notes that AI models, like Reflection 70B, attempt to mimic human reasoning through processes like reflection tuning. However, without a deeper understanding of human cognition, these models remain limited. The conversation touches on the philosophical question of what constitutes reasoning and whether AI can ever truly replicate human thought processes.
The Future of AI: Combining Knowledge and Reasoning
As the discussion progresses, hosts explore the future of AI, particularly the need to combine models that excel at knowledge recall (like current LLMs) with those that excel at reasoning (like AlphaGo). Demis Hassabis of DeepMind is cited, emphasizing that today’s language models are good at storing knowledge but lack sophisticated reasoning abilities. The next step, Hassabis suggests, is to merge these capabilities, creating models that can both reason and recall knowledge effectively.
Luciani and Fredriksson agree, pointing out that the ultimate goal for AI should be models capable of deep reasoning without sacrificing the ability to store and recall knowledge. They also discuss the potential for modular AI systems, where different models specialize in different tasks, collaborating to solve complex problems. This approach mirrors the human brain, where different regions are responsible for different cognitive functions.

AI Rumors: Strawberry and Q-Star
Towards the end of the episode, hosts touch on the much-rumored Strawberry and Q-Star models. Though details are scarce, these models are expected to introduce advanced reasoning capabilities. Possibly through techniques like Monte Carlo tree search or self-taught reasoning. Hosts speculate that these models could represent the next leap in AI development. But they caution against overhyping them before concrete results are available.
Luciani suggests that the AI community is eagerly awaiting a breakthrough in reasoning models. And Strawberry and Q-Star could be pivotal in this regard. However, as the Reflection 70B controversy demonstrates, bold claims need to be backed by solid evidence. As a result, the AI community must remain skeptical until these models prove their worth.

To Wrap Up: Navigating AI’s Transitional Period
This episode concludes with a reflection on the current state of AI. Hosts agree that AI is in a transitional period, where models are becoming increasingly powerful but still fall short in key areas like reasoning. They emphasize the need for continued research and development, particularly in fine-tuning AI models to handle complex tasks.
Fredriksson and Luciani express optimism about the future of AI, believing that the next generation of models will overcome the current limitations. However, they also caution that the AI community must navigate this period carefully, avoiding overhyping models that have not been rigorously tested.
“Reflection 70B, Strawberry, and Other AI Rumors“ offers a thought-provoking discussion on the challenges and possibilities of AI model development. Tune into this episode that highlights the need for transparency, rigorous testing, and an approach to AI’s future, as the field continues to evolve. Don’t miss out!











