
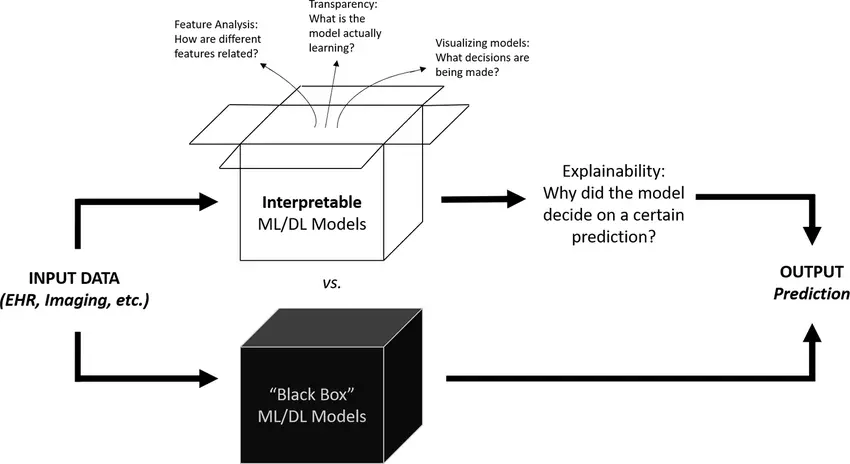
We trust AI to help diagnose diseases, approve loans, and even guide decisions in the courtroom. But here’s the catch: some of the most powerful AI models make these life-altering choices without showing us how they got there. They spit out answers, but keep their reasoning locked inside a black box.
This “black box” problem comes from how today’s AI models—especially deep learning systems—are built. These models learn from huge amounts of data by finding patterns so complex that they often don’t make sense to humans. Even the people who design them can’t always explain how they work.
While explainable AI (XAI) techniques attempt to enhance transparency, many operate in a post hoc manner, offering approximations rather than true interpretability.
Despite continuous advancements in AI governance and model explainability, we still struggle to trust AI-driven decisions. This is due to bias, opaque reasoning, and regulatory gaps. If AI is to be truly reliable, we must rethink how we approach transparency.
What Is the AI Black Box Problem?
The AI black box problem refers to the lack of transparency in how machine learning models, particularly deep learning systems, arrive at their conclusions. Unlike traditional software, machine learning models learn from vast data, resulting in complex internal structures that make it difficult to trace decisions. Deep learning models, such as neural networks, are especially challenging to interpret due to their multiple hidden layers.
In healthcare, a recent review found that 94% of 516 ML studies failed to pass even the first stage of clinical validation tests, raising questions about the reliability of AI in medical applications.
Similarly, in finance, the black-box nature of AI models can lead to ethical and legal challenges. Laura Blattner, an assistant professor of finance at Stanford Graduate School of Business, explains that while AI has the potential to reflect the world’s complexity, its opacity raises practical, legal, and ethical questions.
To address these challenges, researchers explore methods to improve the transparency and interpretability of AI algorithms. One approach is the development of explainable AI (XAI), which designs AI systems that can provide clear explanations for their decisions. For example, an XAI system in healthcare could elucidate the factors leading to a particular diagnosis, such as specific symptoms, test results, and medical history. This enhances trust and facilitates validation by medical professionals.
Why Trust in AI Matters
The AI black box problem refers to the lack of transparency in how machine learning models, particularly deep learning systems, arrive at their conclusions. Unlike traditional software, ML models learn from vast data, resulting in complex internal structures that make it difficult to trace decisions. Deep learning models, such as neural networks, are especially challenging to interpret due to their multiple hidden layers.
In healthcare, AI diagnostic tools analyze medical images and patient data, sometimes outperforming doctors. However, these models often fail to explain their decisions, making validation and treatment justification difficult.
In finance, AI-driven credit scoring models determine loan approvals, often without clear reasons for denials, leading to frustration and potential discrimination.
In law enforcement, predictive policing and risk assessment tools influence bail and sentencing decisions. When based on biased data, they can reinforce inequalities, disproportionately affecting marginalized communities.
Without transparency, AI can amplify bias, make unjust decisions, and erode public trust. To ensure fairness and accountability, we must move toward more interpretable models.
Current Approaches to Explainability
Researchers have been working on ways to make AI more understandable and less of a “black box.” Although these methods provide some clarity on how AI models reach their decisions, they don’t fully solve the transparency issue.
1. SHAP (Shapley Additive Explanations)
Based on game theory, SHAP assigns importance scores to input features, showing how much each contributes to a model’s prediction. However, SHAP values can be computationally expensive and difficult for non-experts to interpret.
2. LIME (Local Interpretable Model-agnostic Explanations)
LIME approximates black box models with simpler, interpretable models for specific predictions. Yet, its explanations vary depending on sampling, making them unstable in some cases.
3. Counterfactual Explanations
These explanations show how small changes to input data would alter the outcome (e.g., “If your income were $5,000 higher, your loan would be approved”). While useful, counterfactuals don’t reveal how the model reached its decision in the first place.
4. Attention Mechanisms in Neural Networks
Common in NLP and computer vision, attention maps highlight which parts of the input data the model focuses on. However, attention does not always equate to causal reasoning – a model can still make incorrect decisions despite highlighting relevant features.
Even with these efforts, explainability is still a significant challenge. Many of the methods offer explanations after the fact, rather than making the models themselves easier to understand from the start. This approach leaves space for uncertainty and the possibility of manipulation.
What We’re Still Getting Wrong
Despite advancements in AI explainability, we’re still making critical mistakes in how we build trust and ensure transparency. The black box problem is not just a technical challenge – it’s an ethical and regulatory one that current solutions don’t fully address.
1. Over-Reliance on Explainability Tools
Tools like SHAP and LIME offer insights, but they often create a false sense of understanding. Their explanations can be inconsistent, complex, or even misleading. Just because a model provides an explanation doesn’t mean it’s truly interpretable or fair.
2. Transparency Does Not Equal Fairness
Having a transparent model doesn’t guarantee fairness. A model might be explainable yet still biased, reinforcing societal inequalities. Interpretability reveals how a model works, but it doesn’t answer whether it should be trusted.
3. The Gap Between Technical and Human Interpretability
What AI researchers find clear – such as feature importance scores – can be incomprehensible to those who rely on AI, like doctors, loan officers, or judges. To build trust, AI explanations must be understandable to its end-users, not just technically accurate.
4. Regulation is Struggling to Keep Up
While laws like the EU’s AI Act and GDPR’s right to explanation aim to promote transparency, they fall short in holding black box models accountable. Without clearer regulations and enforceable standards, AI will continue to make high-stakes decisions with insufficient oversight.
By addressing these issues, we can move closer to building AI systems that are both transparent and truly trustworthy.
The Future of AI Transparency and Trust
Solving the black box problem requires a shift in how we build and regulate AI. Rather than relying on post hoc explanations, the future of AI must focus on inherently interpretable models – systems designed with transparency at their core.
Emerging research in self-explaining AI aims to bridge this gap. These models integrate interpretability directly into their architecture, ensuring that their reasoning is understandable from the start. Techniques like symbolic AI, rule-based learning, and causal inference are being explored to make AI both powerful and transparent.
Policymakers, researchers, and businesses all have a role to play. Regulators must establish clearer guidelines, ensuring that AI-driven decisions are explainable and accountable. Researchers should prioritize human-centered explainability, while companies must move beyond performance metrics and consider the ethical implications of opaque AI.
Ultimately, AI development must shift from “interpretability as an add-on” to “interpretability by design.” Without this change, AI will continue to struggle with trust, fairness, and accountability in real-world applications.
Conclusion: Rethinking AI Trust from the Ground Up
AI now makes decisions that impact lives, but how can we trust systems we don’t fully understand? While explainability methods provide partial clarity, they’re not the full answer. Transparency needs to be built into AI from the start, not tacked on later.
For AI to be truly reliable, it must be accurate, understandable, and accountable. This means prioritizing interpretability just as much as performance. Explainability isn’t optional – it’s essential.
The black box problem won’t solve itself. The real question is:
Will we demand AI that earns our trust, or settle for AI that merely asks for it?











