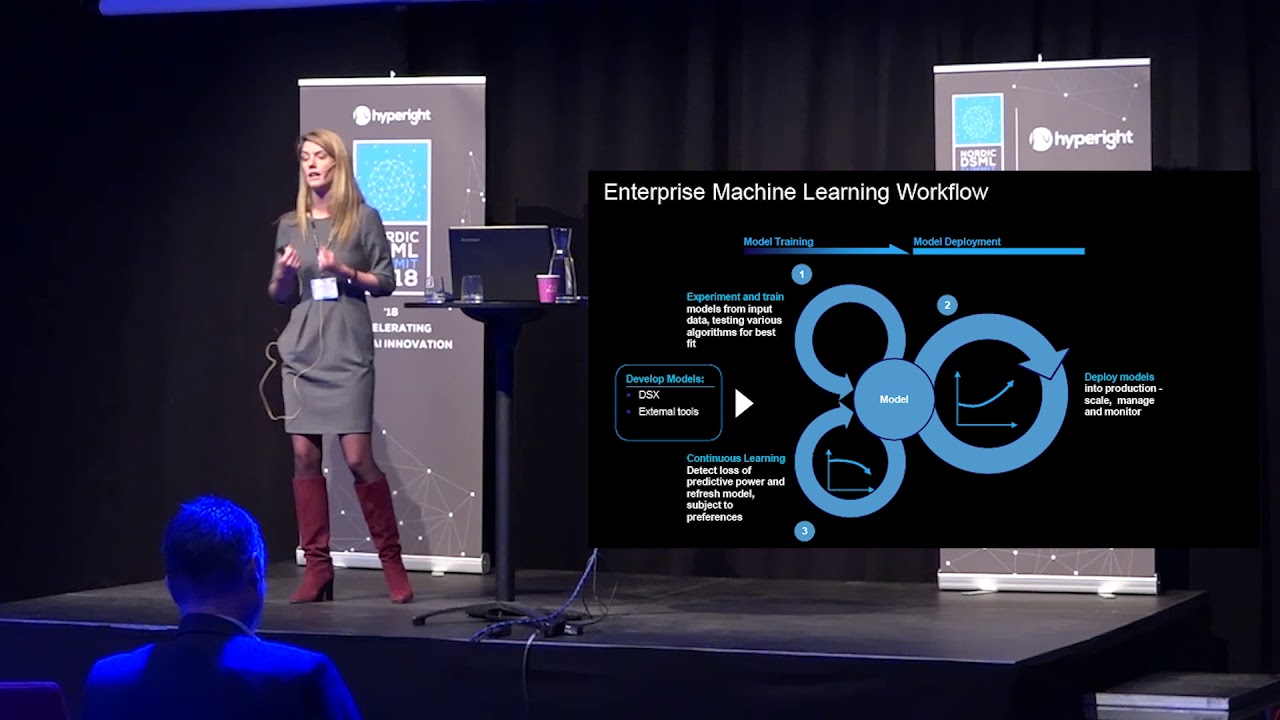
Developing and training distributed deep learning models at scale is challenging. We will show how to overcome these challenges and successfully build and train a distributed deep neural network with TensorFlow. First, we will present deep learning on distributed infrastructure and cover various concepts such as experiment parallelism, model parallelism and data parallelism. Then, we will discuss limitations and challenges of each approach. Later, we will demonstrate hands on how to build and train distributed deep neural networks using TensorFlow GRPC (parameter and worker servers) on Clusterone.
Key Takeaways
- Why machine learning on distributed architecture
- Key frameworks, methods and limitations
- Bringing it to practice with tips and tricks