
Is metadata becoming the new Big Data? As organisations across the globe are advancing their analytical capabilities, and the modern tech stack continues to get more diverse and complicated, the way how data is found, used, and shared within the organisation becomes a challenge for many.
According to some sources, data workers spend around 50% of their time looking for information. It is expected that time will only increase in the future once data is democratised in the organisation and datasets are richer. Based on this, it will be crucial for organisations to find the correct data or dataset to use in a project, model, or report. Therefore, metadata has become one of the most common topics in data management today. Simply put, it is “information about other data” and enables consumers of the data to easily get the information needed to understand and effectively use the data.
In this article, we had the chance to sit down with Mahmoud Yassin, Senior Data Manager at Booking.com, and talk more about the difference between data and metadata, how metadata is generated, its benefits, and how metadata is managed. Moreover, we’ll find out what Metadata Lake is and how organisations can utilise such an approach.

Mahmoud Yassin: My name is Mahmoud Yassin and I am originally from Egypt. I have been working in the data field from the first day of my career. I have started as an ETL (Extract, Transform and Load) developer in the telecommunication business. After that, I realized that I need to know BI (Business intelligence) to have an end-to-end view of how to use data in a correct way. I stepped into big data architecture as well and loved being in the design seat. I continued working in the telecom industry for more than 10 years moving between multinational operators across Africa and Asia. After that, I decided to move to Europe to explore a new business, so I chose the financial industry where I worked first as a consultant and later, I worked for a Dutch bank called ABN AMRO and now I work for Booking.com as a Senior Data Manager
Hyperight: During this edition of the Data 2030 Summit, you will share more on the “Role of Active Metadata Lake in any successful data architecture”. What can the delegates at the event expect from your presentation?
Mahmoud Yassin: Metadata is the key to any successful data journey. Metadata is so often neglected topic and this is a fundamental mistake that I aim to explain more about how to use it and how to turn it in a positive manner towards your data journey/strategy. I will cover the definition of metadata, types of metadata, ways to utilize metadata towards data strategy and provide some use cases that showcase the potentials of using metadata actively.
Hyperight: As Metadata Lake is a great and upcoming topic, and not many organsations have started working with it, it would be exciting to grab this opportunity with you to capture the essence of what Metadata Lake is and how can organisations utilize such an approach? But to start with, can we first define the difference between data and metadata, how metadata is generated, and how traditionally is stored or handled?
Mahmoud Yassin: Metadata is data about the data itself. Metadata gives true meaning to the data and without it, data can be useless. Let me give you an example, if you got an excel sheet with some numbers in it like the first column without a header:
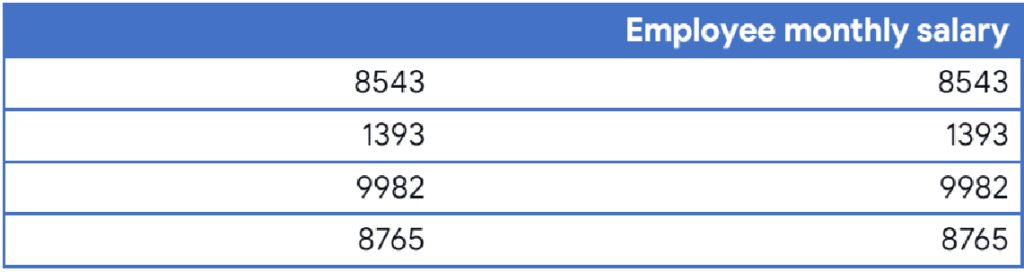
Can anyone tell me what those numbers represent? Does it represent a street number, salary, measurements? If we just add a title like the second column all the numbers will start to make sense.
Metadata can describe and help understanding the real data. Metadata is the key to unlock value out of data.
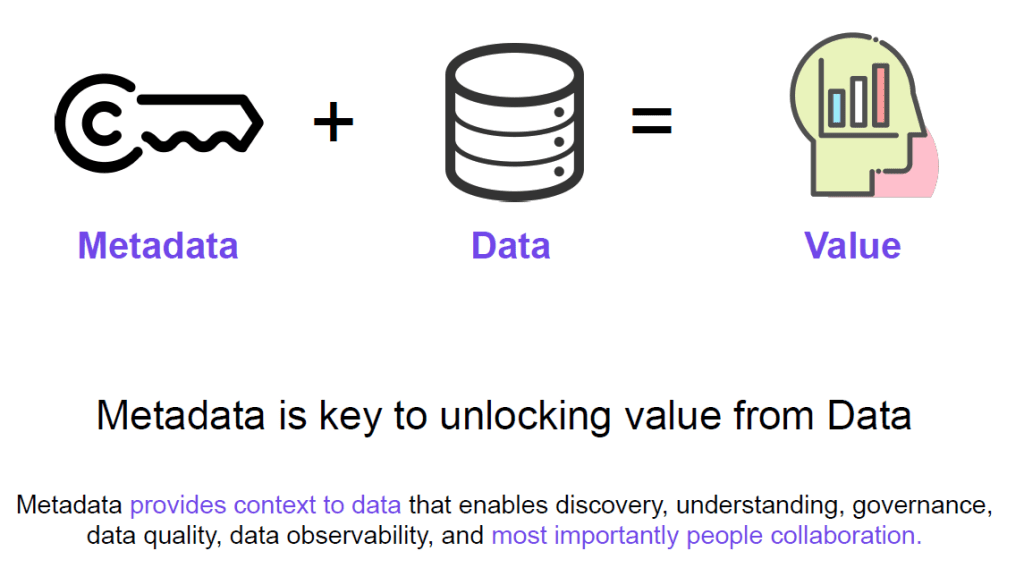
Metadata can be generated at any point in the data lifecycle. It can be defined as a data definition language while designing any data model that is classified as (Technical metadata). Think of the DDL of your tables in the database where you specify the data types like (int, char, date, datetime etc). You can generate metadata while doing some data movement or data transformation via the generated logs that are classified as “Operational metadata”. Metadata can be generated as part of your data governance processes that is classified as “Business metadata”. Think of the name of a data owner or a data steward.
Metadata is being generated as stated above at any life cycle of your data journey. Many organisations just don’t have a vision on the great value of gathering and maintaining all types of metadata and how this metadata can dramatically improve the data strategy and execution of being more data-driven. That’s why metadata is sort of neglected, while harvesting and using it, can add big value.
Hyperight: What are the benefits for organisations of having and using metadata and why it is getting more important and crucial for organisations to focus on this topic?
Mahmoud Yassin: Let’s get practical. I will share a use case that demonstrates few of the possibilities of metadata. I have worked on a project where we harvested the technical metadata out of our BI (Business intelligence) tool.
We got tons of metadata stored in JSON format, after understanding the metadata and reverse engineering it, we managed to store and query the metadata while defining some of the below KPIs that helped us a lot to improve:
- What are the different data types that are being used across the organisation to produce a report or a dashboard è with this KPI, we found big percentage of the organisation are using ungoverned data source to report on data and moreover we found a lot of datasets that is being stored and used from a personal laptop or a local drive that contains sensitive information!
- The most used data sources to develop dashboards on the organisation level è with the KPI, you can reach out to the data owner(s) of the data source and improve the way of storing the data to fit the high demand on it or you can suggest to cache this data to improve the performance on it.
- End-to-end lineage up to column-level, where we can show per report/dashboard, how the data is being used and what kind of columns are being generated or used + the transformation rule that was applied on it.
- An easy way to navigate towards any report or dashboard, is to check the details to promote more transparency in dealing with data, stimulate sharing knowledge and exchange ideas.
- Top 10 reports ordashboards, along with the time it takes for them to run. After identifying these key reports, we implemented substantial technical enhancements, which enabled the organization to make quicker decisions based on these reports compared to the usual process.
Hyperight: In your presentation, you are presenting a new data architecture concept called Metadata Lake, or data lake only for metadata. Can you explain what Metadata Lake is and what is the purpose of it?
Mahmoud Yassin: Metadata Lake is an architecture proposal that will have the ability to enable the capturing, management of the origins, movement, characteristics and transformations of data as it moves through the organisation across various systems, processes and people to support the data lineage needs and some data governance reporting.
Metadata Lake needs to:
- Store all types of metadata (business, technical, operational and social) coming from all your company systems that are needed for lineage and all the supported use cases.
- Combine the metadata when needed to create a complete data set without creating a new dataset.
- Integrate the connected metadata parts to show lineage across systems.
- Generate new insights driven from metadata to support operation excellence, regulatory requirements and to show compliance.
- Profile the harvested metadata to check the quality of it.
- Verify if the harvested metadata is correct, accurate and delivered based on SLA.
- Process all kinds of different metadata in the lake for future use.
- Secure access to the metadata if needed to be exposed.
Hyperight: Why did you decide to take this approach? What challenge or opportunities you wanted to address?
Mahmoud Yassin: We have decided to take this approach as we have seen the true value of utilizing the metadata, and how we can use it actively to improve the way of working and increase the data opportunities.
One of the main challenges in this field is to find clear definitions and guidance on for example the types of metadata, which I am explaining in detail in one of the below paragraphs.
Another challenge after realizing all types of metadata, is how to store such data in one central place, and how all types can be linked together, and this was the core reason for thinking about creating a dedicated lake for metadata.
Harvesting the metadata is also a big challenge looking at the scale of systems that is being used in big organisations.
Hyperight: Can we dive deeper into the architecture and how the Metadata Lake fits with your overall modern data stack?
Mahmoud Yassin: Metadata Lake fits naturally into our data strategy, as it helps us gather the required data to improve what we offer, and also improve the way we offer data towards our stockholders.
Hyperight: What would you say are the main characteristics of such Metadata Lake?
Mahmoud Yassin: Metadata Lake needs to support all types of metadata and allows you to traverse vertically and horizontally though it, and this is one of the biggest challenges in this area, but first let’s understand the various types of metadata:
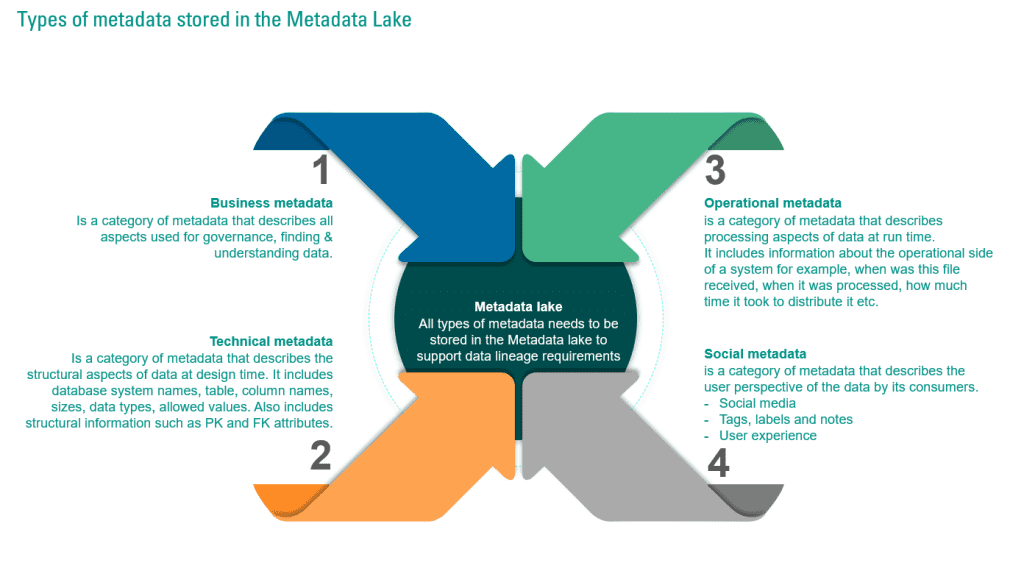
Business metadata – is a category of metadata that describes all aspects used for governance, finding, and understanding data.
Technical metadata – is a category of metadata that describes the structural aspects of data at design time. It includes database system names, table, column names, sizes, data types, allowed values. Also includes structural information such as PK and FK attributes.
Operational metadata – is a category of metadata that describes processing aspects of data at run time. It includes information about the operational side of a system for example, when was this file received, when it was processed, how much time it took to distribute it etc.
Social metadata – is a category of metadata that describes the user perspective of the data by its consumers.
- Social media
- Tags, labels and notes
- User experience
Hyperight: Your presentation is based not just on theoretical, but also on practical experience when we speak about Metadata Lake. Can you share some of the lessons learnt from the use cases you had regarding applying Metadata Lake in organisations?
Mahmoud Yassin: We have been working on the Metadata Lake architecture for more than two years now. We have encountered many challenges, but also learned a lot. Below are some of the tips that I would like to share with all of you:
- Don’t underestimate the possibilities of metadata and what it can bring to your organisation.
- Try to implement the Metadata Lake architecture in the cloud as you will need the flexibility that the cloud provides to achieve this complex goal.
- Look towards NOSQL technology if possible as your main backend data layer.
- It is hard to harvest the metadata out of the various systems that run on different technologies so think of the available tools/technologies in the market that can help out in getting the metadata.
- Tools like AWS Glue and Microsoft Purview are evolving a lot and can be of great value.
Hyperight: What are your recommendations to those organisations that are interested not just in using metadata, but also in building data architecture for their metadata? Where should they start, and what to pay attention to?
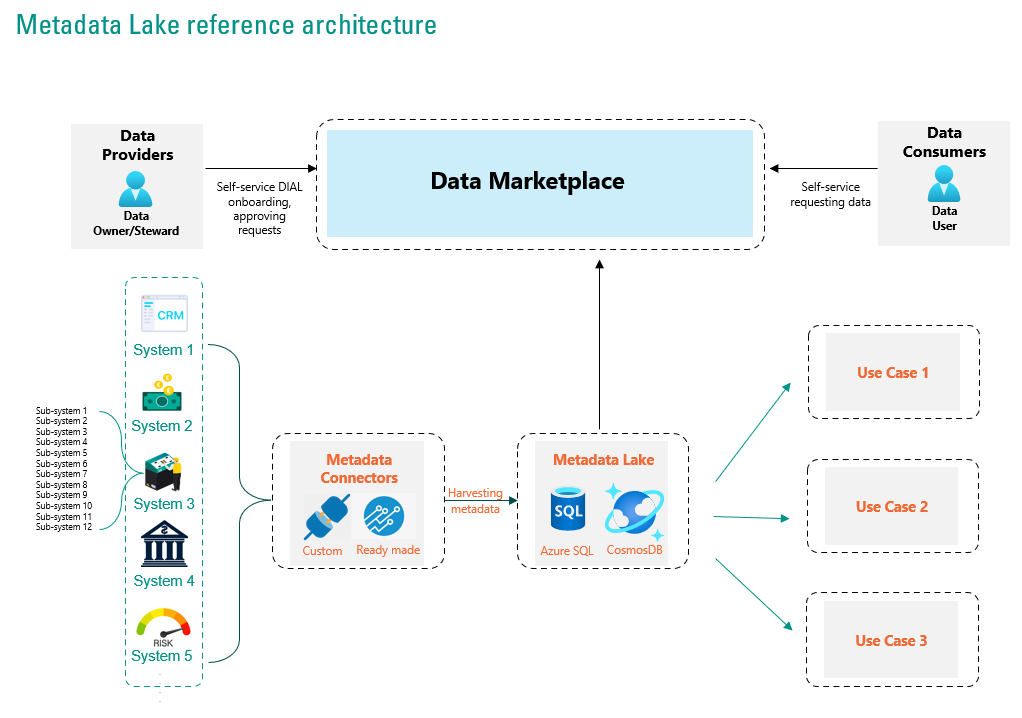
Mahmoud Yassin: You don’t need to start from scratch. Below is a reference architecture that can be used to inspire you of how such an architecture may look like:
Hyperight: We’ve had presentations and articles at our events addressing the history of the data architectures, from a data warehouse to a data lake to a data lakehouse. From your perspective, how do you see the future of data architecture? Any trends you see more of in the upcoming 1 – 2 years?
Mahmoud Yassin: Data Mesh is one of the hottest data architectures that is being discussed on a massive scale. Data Mesh challenges the traditional/classical thinking of how to store and manage data in a central place called data warehouse or data lake.
Data Mesh is introducing a denormalized approach of storing, processing and sharing data across what is called ‘Domains’ and dealing with data as a ‘Product’ while keeping a ‘federated governance’ layer on top.
You can reference to my presentation where I have explained in details more about the trends of data architectures and with focus on Data Mesh: https://youtu.be/celFSdQRhEE









