
It is already well known that organizations can optimise their performances with analytics. Analytics in the banking sector has an even more crucial role, mainly because of the abundance of data these organizations work with.
Having the right analytics platform to prepare financial institutions to embark on this journey is also essential. When it comes to that, organizations can choose between building these tools in-house or getting them from the shelf (buying them). Both approaches have their advantages but also challenges.
In this interview, we had a unique opportunity to sit down with Trung-Duy Nguyen, Data Engineer and Benjamin Tapley, Software Engineer from DNB Bank ASA and discuss their journey of building an in-house analytics platform. It is a platform built and used for a variety of ML and analytics use-cases in the bank – everything from pricing model mortgages, SME pricing model credit, AML- visualisation networks, wealth management.
Hyperight: Can you tell us more about you? What are your professional background and current working focus?

Trung-Duy Nguyen: I graduated from a master program in Data Science and Engineering, and I have developed scalable Big Data & Analytics systems for several years. I am currently a Data Engineer in the Data & Analytics Platform team at DNB, and my daily jobs are to maintain and enhance the reliability of data science workflows (data pipelines, data science workbench, productionizing machine learning models etc.) for hundreds of data science users across teams and departments inside the bank.
Besides that, I love to learn and share best practices in the data world, so I also participated in building up the internal Data Engineering/Science community in my workplace.

Benjamin Tapley: I have been working as a software engineer on DNB’s Analytics Platform for one year and work with the implementation and maintenance of various cloud services that are offered by the Platform. Previously, I studied maths and physics where I’ve researched high-performance geometric numerical methods for solving differential equations with application to problems in physics and engineering. I am interested in scientific computing and machine learning.
Hyperight: During this edition of the NDSML Summit, you will share more on “Building a scalable and centralized Analytics Platform for Norway’s largest bank”. What can the delegates at the event expect from your presentation?
Trung-Duy Nguyen: As the only centralized Platform for analytics and data science in the bank, we make a lot of decisions from strategies to architecture. Most of those decisions have vital impacts on professional data science practitioners in the bank, whose work affects millions of people in Norway. In this presentation, we would like to share our journey building the Platform, and how we improve from there. Many enterprises out there are focusing on building data & Analytics Platforms. We hope this presentation can be useful for people before or on the same journey.
Hyperight: Why did you decide to build an in-house Analytics Platform on the Cloud for DNB Bank ASA instead of buying an off-the-shelf solution?
Benjamin Tapley: Committing to an off-the-shelf solution can offer several advantages such as quick implementation, low maintenance costs, professional support and SLAs to guarantee a certain level of operation and functionality. However, with such a diverse range of data science teams at DNB working on an equally diverse range of use cases, we felt that no single Platform was suited to our purposes. Our priority is to treat each project on equal footing and maintain the ability to add new features as required. In other words, we prioritise flexibility, which is seldomly offered by an off-the-shelf Platform. This removes any limitations that locking oneself into a buy-in Platform may impose. There are of course other benefits to our approach, such as lower long-term costs, support for multiple languages, utilising open source, and modularisation allowing us to swap components as we need.
Hyperight: Can you tell us more about the lessons learned from the user’s experience while building the Analytics Platform?
Benjamin Tapley: One lesson that we have learnt is that documentation is also paramount to ensure usability on the Platform and that this task is never ending. This is especially important for a Platform that is built in-house, which comes without professionally written documentation. The Platform is used by many with varying technical competency, meaning that clear and comprehensible documentation is a requirement for any new task to be considered complete. However, it is a continuing challenge to: (1) find the optimum balance between conciseness and comprehensiveness; and (2) keep the documentation well-organized and searchable. There are many practices in place to mitigate technical debt, but documentation debt is equally as important as this is often paid off by the Platform users who generate value for the bank. In addition, relying on agile methodologies is important to implement ideas, receive feedback, fail fast and iterate quickly and purposefully.
Hyperight: What is the importance of the Platform today for the organization?
Trung-Duy Nguyen: We are extremely proud of the crucial role our Analytics Platform has played in transforming data science workflows inside the bank. In doing so, we have established data democratization, which treats data as a first-class citizen and allows every employee the ability to access and experiment with data science. There are currently more than 300 data science users (data scientists, analysts, engineers etc.) who are writing code, running machine learning models, and developing analytics apps on our Platform. Most of the business use-cases that we have onboarded to the Platform are: Personal Banking, Corporate Banking, Wealth Management, Markets and more. As a result, we have successfully launched to production ML models that are crucial to the business decisions of the bank:
- Standardize and mordernize the data workflows from legacy systems, offering scalibility and reliability
- Real-time prediction models served via APIs to support pricing applications
- Statistical models for Batch prediction across business units providing churn prediction to customers, thus, leads to the next strategies and offers
Hyperight: In your presentation, you will focus on the daily workflows of data science users in your company and the development of the Platform capabilities to facilitate their data science projects. What are those common data science workflows, and how important are they for the Analytics Platform to be scalable (and governance)?
Trung-Duy Nguyen: Let’s be realistic. We do not do Analytics and Data Science in a magical and fancy way as you may read from some newspapers, which is pouring data into black boxes and then instantly generating revenues. The workflow is mostly the same as other data-driven companies. First, we consider which data science practitioners get access to data sources. Next, they perform analyses and experiments using various statistical/machine learning models until they are happy with results. Finally, model productionization is considered.
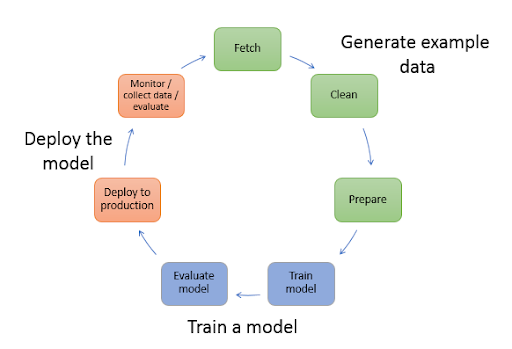
In terms of being scalable, here are some aspects that we offer to users to facilitate their workflows:
- Framework and languages: We have numerous analysts and engineers who come from diverse backgrounds. We deliver toolkits to ease the user experience; for example, we support Python & R on equal terms by offering both VSCode and RStudio as IDEs, then users will pick one that they are confident with.
- ML pipeline as a Service: We offer ML pipeline templates including stages from Data Extraction to API serving. The goal of ML pipeline as a Service is to deliver on MLOps. This gives data scientists/analyst more time to experiment without worrying about deployments, where the users work on the logic, then our Platform team handle the infrastructure
- Computing instances: There are many use-cases which require extra computing power, such as GPUs. The Platform offers a wide range of computing instances (CPUs, GPUs, etc.) to help reduce the user’s time spent in analysis.
- Resource utilization and monitoring: Since everything is running on the cloud, the awareness of cost optimization is critical to both users and our Platform. Thus, we have developed an alarming framework to notify and monitor cloud resources, which allows us to control and estimate budgets of the giant Platform.
Hyperight: What are your final recommendations for organizations interested in building an in-house scalable and centralized Analytics Platform? What should they pay attention to?
Benjamin Tapley: The focus of the Platform must always be those that are using it. We have found it very helpful to have an unimpeded and open communication channel directly between the users and the Platform owners. This ensures a fast feedback loop enabling us to iterate quickly, minimise Platform down time and maximise user productivity.
Hyperight: From your perspective, how do you see the future of Big Data and Analytics systems? Any trends you see more of in the upcoming 1 – 2 years?
Trung-Duy Nguyen: In my humble opinion, there are some interesting trends to watch. The first one would be “the analytics/ML Platform is more tightly coupled with data engineering”. Since increasingly many data science teams are shifting toward a data-centric approach, there is a rising need for data reliability, which demands a proper setup of data monitoring services. Data scientists/analysts are free to define data quality metrics and collaborate even more closely with the data engineering team to track those metrics. The second topic, which is worth mentioning, is “real-time/online machine learning will gain more traction”. As many data professionals believe that the fresher the data, the better the outcomes from models; thus, streaming frameworks such as Kafka, Pub/Sub, AWS Kinesis will be the core component of this trend. In practice, developing a scalable streaming data pipeline is challenging; however, for us, as the Platform owner, we need a roadmap to build this service properly and to support online learning use-cases which is likely to play an important role in the near future.











