
Synthetic data has become an emerging topic in the artificial intelligence (AI) world.
More than ever, organizations turn to advanced analytics and AI to optimize their operational process, enhance customer experience or innovate new products and services. But, to stay competitive in today’s landscape using these capabilities, organizations need bigger access to internal and external data – a resource that is hard to find, not always available, and sometimes tricky to use. Especially customer data. Given the increased emphasis on data protection and AI ethics in Europe, many organizations have started deescalating their AI innovation efforts. They wonder how to maintain competitiveness in the algorithmic economy when data is abundant, but can not be used to train models.
That is why most professionals agree that synthetic data has value to address these issues. To better understand the value of synthetic data, we’ll open some of the fundamental questions in this article: What is synthetic data? How is it generated? Who benefits the most? And are there any valuable examples from everyday life?

What Is Synthetic Data and How Is It Generated?
Synthetic data is data that is artificially created by ML algorithms instead of generated by actual events. It can be used for a wide range of activities, such as testing data for new products and tools, or adding more complexity in AI training models.
Many sources identify different types of synthetic data for various purposes. One article by Statice explained the three common types:
- Synthetic text
- Synthetic images and videos
- Tabular synthetic data
Synthetic data is typically created via a generative model from the original dataset that produces synthetic copies resembling accurate data. The main generative models for synthetic data are Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Autoregressive models.
If it needs to be simplified, synthetic data can be generated when there is not some or many real data. If there is no actual data, but a broad understanding of data set distribution, a random sample of any distribution can be created. The synthetic data’s quality depends on the engineer’s grasp of a specific data environment. Where real data does not exist, synthetic data can be the right solution. When there is real data, synthetic data is generated by a best-fit distribution. A hybrid synthetic data generation approach is used when only some real data exists, where part of the dataset is generated from assumed distributions and other parts from actual data.
What Are the Advantages and Disadvantages of Synthetic Data?
Organizations have more data than ever at their disposal, but the critical challenge is how to use the insights from the datasets for impactful solutions.
Organizations use big data tools and advanced analytics applications to generate value from their massive datasets. Synthetic data has a significant role in the development and improvement of critical applications.

Some of the advantages of synthetic data include:
Cost – With synthetic data, it becomes cheap and fast to produce new data once the generative model is set up. Collecting synthetic data is more cost-effective and efficient than collecting real data. It is said that this is especially applicable to the autonomous vehicle space, where it is expensive and time-consuming to collect real data.
Privacy – Real data may have usage constraints due to privacy rules or other regulations. Synthetic data can replicate all-important statistical properties of real data without exposing real data, thereby eliminating the issue. With personal information being removed, the data can’t be traced back to the original owner, so copyright and privacy infringements can be avoided. This is critical in synthetic data machine learning applications where realistic user behaviors are being simulated, and private information must be protected.
Testing – Synthetic data can play an important role in system training. Synthetic data is used to examine existing system performances but to train new systems on scenarios that are not represented in the real data as well. Synthetic data has the immunity to some common statistical problems, like item nonresponse, skip patterns and other logical constraints.
Synthetic data has various benefits, but it also has limitations. Some of them can be:
Output accuracy – Synthetic data only mimics the real data, it is not a replica, so it does not copy the original content exactly. This means that synthetic data may not cover some outliers that original data has.
Quality of the synthetic data is closely connected with the data source and data generation model that created it. Biases in the source data can be reflected in the synthetic data.
Verification server is needed to ensure the system has been appropriately trained and is not generating outputs due to assumptions built into the synthetic data.
Synthetic data generation requires time and effort – Though easier to create than actual data, synthetic data can still be time consuming and costly, if done right.
User acceptance – Many organizations may have cultural resistance regarding the adoption of the concept of synthetic data, so it may not be accepted as valid by users who have not witnessed its benefits before.
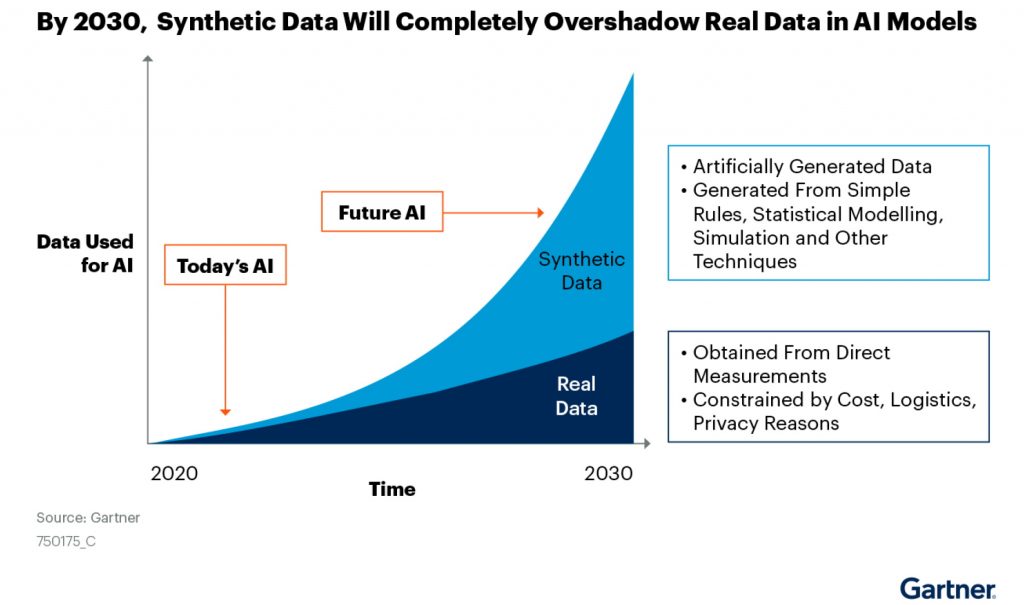
Based on Gartner‘s estimations, it’s expected that by 2024, 60% of the data used for the development of AI and analytics projects will be synthetic data.
Mostly AI claims that synthetic data can retain 99% of the information and value of the original dataset while protecting sensitive data from re-identification.
Who benefits the most from synthetic data? Positive experience can be found at automotive and robotics, financial services, healthcare, manufacturing, national security, and social media. Business functions that can benefit from synthetic data include: marketing, ML, agile development and DevOps, HR and others.
Everyday Examples of Synthetic Data Usage
The best way to understand the value of synthetic data is to showcase some everyday examples.
It is said that Denmark and the other Nordic countries have high-quality health data that has the potential to enable the healthcare sector to detect diseases early, improve diagnosis, and create treatments tailored to individuals.
Finding new treatment options by analysing large quantities of data can be a problem for the healthcare sector because of the inability to share data. The University of Copenhagen is developing a method that can use original data to generate synthetic datasets to address this problem. The Novo Nordisk Foundation supports the project “Synthetic Health and Research Data (SHARED)” that should create synthetic data to be shared without compromising data security.
Another example is the Norwegian Survey on living conditions/European Health Interview Survey (EHIS). Due to confidentiality policies at Statistics Norway and the sensitive nature of health data, a new method takes advantage of the rich register data to establish synthetic data in a model-free way.

“Hey, Alexa, how do you work?”. Now we know, though. Alexa is built based on natural language processing (NLP) that converts speech into words, sounds, and ideas. Amazon is using synthetic data to train Alexa’s language system. While talking about Amazon’s investment in generating synthetic data for its products and services, it is worth mentioning that Amazon Go also uses synthetic data to train cashierless store algorithms.
Similar examples are Google’s Waymo which uses synthetic data to train its autonomous vehicles, and the Toyota Research Institute for their dynamic scene understanding, specifically for autonomous driving.
One good example for the security of financial transactions is American Express, which uses synthetic financial data to improve fraud detection. The San Francisco-based company States Title uses synthetic data for faster and safer real estate transactions.
The number of user cases that benefit from the synthetic data for their developments is constantly increasing.
Conclusion
The creation and usage of synthetic data will only grow as our data becomes more complex and more closely guarded.
It is legitimate to ask, who else may benefit from synthetic data, which industries and companies, and how individuals can use synthetic data in their personal lives?
Despite its limitations, the benefits are functional and apply in many cases.









