
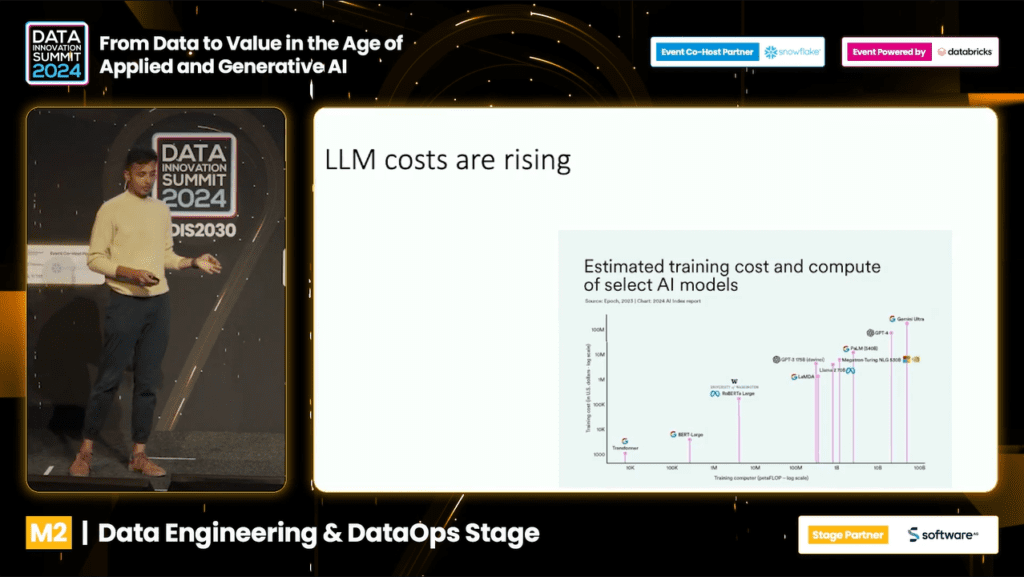
The rise of Large Language Models (LLMs) such as GPT-4 and Gemini Ultra comes with increased costs associated with their training and deployment.
With training costs reaching $78 million for GPT-4 and $191 million for Gemini Ultra, the need for efficiency in LLM deployment is more critical than ever.
Aditya Jain, Applied Research Scientist at Meta Platforms
In this article, we take a look at a presentation at the Data Innovation Summit 2024. This talk by Aditya Jain, Applied Research Scientist at Meta Platforms, tackles the feasibility of running large language models on a single GPU, offering cost-effective alternatives to reduce costs while maintaining comparable performance.
Why Efficiency Matters in Large Language Models?
As the popularity and demand for larger models grow, the associated costs are inevitably passed on to the customers, leading to higher prices for model calls using APIs.
As of January 2024, there has been a 600x difference between the most expensive and cheapest model for inference, with the former being models like GPT-4 with a 32k context length and the latter being more efficiently served models like Mistral.
Aditya Jain, Applied Research Scientist at Meta Platforms
The Single GPU Hypothesis
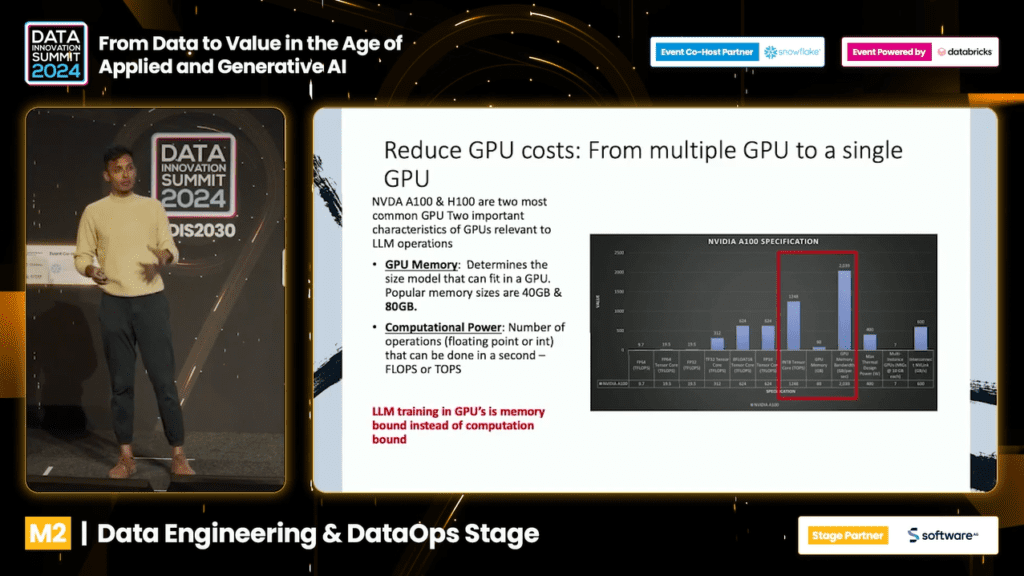
Major costs associated with LLMs are GPU’s. By leveraging a single GPU, specifically high-memory variants like Nvidia A100 and H100, organizations can potentially reduce these costs significantly without comprising performance.
Two key GPU characteristics affect LLMs: memory capacity (VRAM, usually ranging from 40 GB to 80 GB) and computational power (popularly measured in Floating Point Operations Per Second (FLOPS) or more generally in Operations Per Second).
Understanding GPU Constraints
In the context of LLM training, memory capacity is often the limiting factor rather than computational power. For instance, a model like Llama 2 with 7 billion parameters requires about 14 GB of memory for inference, fitting comfortably within the 80 GB VRAM of an A100 GPU. However, training even a batch size of 1 can require upwards of 70 GB, due to the additional memory needed for activations, gradients, and optimizer states.
Training on a Single GPU
Training a LLM like Microsoft’s Phi2, a 2.7 billion parameter model, on a single A100 GPU is theoretically possible as it occupies around 50 GB of memory for a batch size of 1. However, training on such a massive dataset (1.4 trillion tokens) would take an impractically long time. Hence, time to train (measured in GPU hours) becomes a critical factor alongside memory and computational efficiency.
Reframing Efficiency
While fitting LLMs on a single GPU is necessary, organizations need to introduce the concept of GPU Hours into efficiency considerations. The goal shifts from merely fitting the model into the GPU to completing the training within a feasible time frame, such as a single day(s) – the time largely governed by the budget for the project. This reframed objective requires balancing memory and computational power with the amount of data processed.
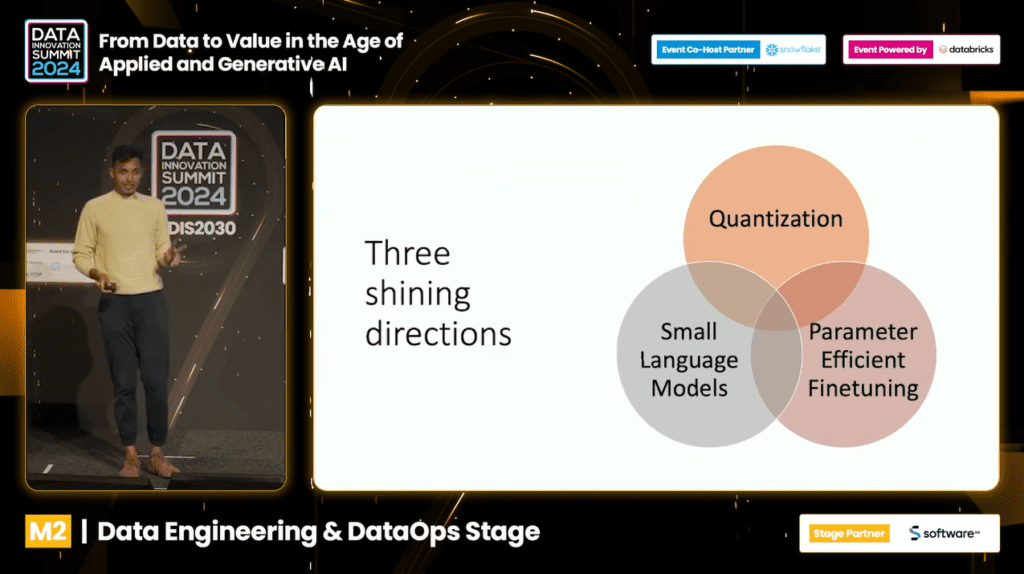
Three Major Directions for Optimizing LLMs
Optimizing Large Language Models (LLMs) to run efficiently requires innovative techniques that address memory constraints, computational power, and performance. According to Aditya, there are three strategies to achieve this goal:
1. Quantization
Quantization reduces the memory footprint by storing model parameters in smaller data types. For example, floating point 32-bit (fp32) numbers are standard but take up more space. Using smaller formats like fp16, fp8, or even integer types can significantly decrease model size without losing much performance. Benefits:
- Memory Efficiency. Quantization can shrink the model size to fit within the memory limits of a single GPU. For instance, Llama 70B’s original size in fp16 is 138 GB, which exceeds an 80 GB GPU’s capacity. However, quantizing it to a 4-bit format reduces the size by 75%, making it feasible for a single GPU.
- Faster Inference. Smaller model sizes lead to increased throughput (tokens per second) and reduced costs, as more batches can be processed simultaneously.
Key Insight: Effective quantization methods can maintain model quality while significantly reducing memory requirements and improving throughput. Techniques like fp8 and int8 quantization have shown that models retain their performance even with reduced precision. Different quantization methods and libraries vary in effectiveness, and choosing the right one depends on the specific use case. Generally, larger quantized models can perform better than smaller non-quantized models.
2. Small Language Models
Smaller models, like Microsoft’s Phi2, can outperform larger models like Llama 70B on specific benchmarks despite being significantly smaller and trained on less compute. The secret lies in data quality and model initialization techniques. Benefits:
- Data Quality: High-quality data, akin to how human children learn language, plays a crucial role. Microsoft’s approach of using textbook-quality data and synthetic datasets created by GPT-4 leads to better model performance.
- Model Initialization: Using previous model versions and rescaling weights for initialization helps transmit knowledge and improves performance.
Key Insight: Smaller models can achieve high performance by focusing on high-quality data and effective initialization techniques. This approach can lead to models that punch above their weight class in terms of size and computational requirements. Operating in the data-optimal regime (focusing on data quality) rather than the compute-optimal regime can yield better results for smaller models, making them a cost-effective alternative to larger models.
3. Parameter-Efficient Fine-tuning (PEFT)
Fine-tuning a model for specific tasks can significantly enhance its performance. Parameter-efficient fine-tuning (PEFT) methods focus on adjusting only a small fraction of the model’s parameters, making the process more memory-efficient. Benefits:
- Specialized Performance. Fine-tuning allows models to excel in specialized tasks, such as sentiment analysis or domain-specific applications.
- Memory Efficiency. PEFT methods, which change only 1-6% of the parameters, reduce memory requirements, enabling larger batch sizes and faster training times.
Key Insight: PEFT methods can achieve comparable or superior performance to full fine-tuning while using a fraction of the memory. Techniques like LoRA (Low-Rank Adaptation) have shown that by adjusting fewer parameters, the model can be adapted efficiently with less computational overhead. Fine-tuning is particularly beneficial when the base model’s performance is below 50% for the target task. In such cases, there is substantial room for improvement. PEFT methods make this improvement accessible even with limited hardware resources.
Large Language Models: How to Run LLMs on a Single GPU
LLM training/inference is bound more by GPU memory than computations in the current regimes. Compute used in metrics of GPU hours is a better measure of efficiency than fitting models in a single GPU. To reduce memory, organizations can do two things: they can quantize things or they can just use smaller models. And to increase performance, organizations can fine-tune the model using a much smaller data set. And use parameter-efficient fine-tuning techniques.
Organizations can combine different efficiency techniques to get the benefits of many of them to reduce our cost further, and this is more art than science; there are no best practices so far on this.
Aditya Jain, Applied Research Scientist at Meta Platforms
Disclaimer: The content of this presentation reflects Aditya’s personal opinions and is in no way affiliated with Meta or its activities. It is an independent perspective.
For more information, tune into Aditya’s presentation on Large Language Models on a Single GPU at the 9th annual Data Innovation Summit!











