

For the past several years, the artificial intelligence industry has been engaged in a relentless pursuit of scale. Every major breakthrough has been accompanied by larger models, more parameters, longer context windows, and increasingly impressive demonstrations of what generative AI can accomplish. Whether it is writing software, conducting research, generating content, or reasoning through complex problems, the prevailing assumption has been remarkably consistent: intelligence emerges through scale. If we can continue to train larger models on larger datasets using larger amounts of compute, then AI systems will continue becoming more capable, more useful, and eventually more general.
Yet beneath this widely accepted narrative lies a question that deserves far more attention than it currently receives. What if intelligence is not the primary bottleneck anymore? What if the greatest limitation of today’s AI systems is not their ability to reason, but their inability to remember?
That question sits at the center of yesterday’s AI After Work (AIAW) Podcast episode with Johan Thulin, Co-Founder and CTO of Aphygo , whose work challenges some of the fundamental assumptions that underpin modern AI development. While much of the industry remains focused on scaling foundation models, Johan argues that the next major breakthrough may come from an entirely different direction. The future may belong not to the systems that know the most, but to the systems that can accumulate knowledge, retain context, learn from experience, and continuously adapt over time.
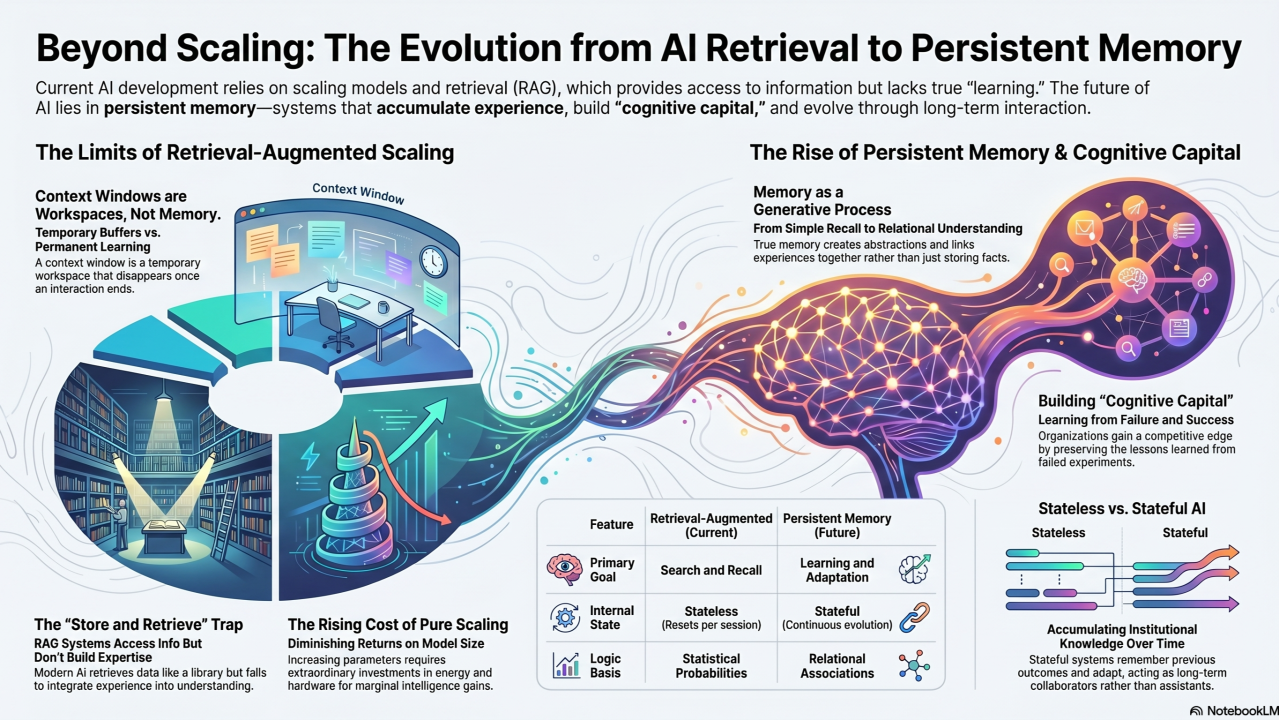
The distinction may sound subtle, but its implications are profound. Modern AI systems appear intelligent because they have absorbed enormous amounts of information during training. They can discuss history, write code, summarize scientific papers, and engage in remarkably sophisticated conversations. Yet despite these capabilities, they remain surprisingly transient. Most interactions exist within a context window. Once that context disappears, so does much of the system’s ability to maintain continuity. Even when memory features are introduced, they are often implemented as retrieval mechanisms rather than genuine memory structures. The result is a class of systems that can access information but struggle to build understanding from experience.
As Johan observed during our conversation, much of today’s AI memory architecture is fundamentally built around retrieval rather than learning. Describing the dominant Retrieval-Augmented Generation paradigm, he summarized the challenge in a single sentence: “They don’t learn, they store, they retrieve.”
That observation may ultimately prove more important than many enterprise leaders currently realize.
The Context Window Is Not Memory
One of the most significant misconceptions in today’s AI landscape is the growing tendency to equate larger context windows with memory. As foundation models gain the ability to process hundreds of thousands or even millions of tokens, it becomes tempting to believe that the memory problem has largely been solved. If an AI can read an entire codebase, thousands of pages of documentation, or years of corporate reports within a single context window, surely it has memory.
But memory and context are fundamentally different concepts.
A context window is a temporary workspace. It is a buffer that exists during an interaction and disappears when that interaction ends. While increasingly sophisticated retrieval systems can reintroduce information into future conversations, the underlying architecture remains largely unchanged. Information is searched, retrieved, ranked, and injected back into the context. The system gains access to relevant information, but it does not necessarily integrate that information into an evolving understanding of the world.
This distinction becomes increasingly important as organizations move from simple chatbot deployments toward agentic systems capable of operating over extended periods of time. A customer service assistant can function reasonably well with limited memory because each interaction is largely self-contained. A long-term research assistant, autonomous software engineer, or strategic business advisor faces a very different challenge. Such systems must understand previous decisions, remember historical outcomes, learn from mistakes, adapt to changing environments, and accumulate knowledge over months or even years. These capabilities require something that resembles memory far more than retrieval.
The challenge is becoming increasingly visible as enterprises deploy AI agents into real-world workflows. Initial demonstrations often appear impressive. The agents retrieve documents, generate responses, and execute tasks with remarkable competence. Yet over time many organizations discover a frustrating limitation. The systems repeatedly encounter similar situations without becoming significantly better at handling them. They access information but fail to develop expertise. They execute workflows but struggle to build understanding. They can retrieve knowledge, but they do not appear to learn from experience.
This is where Johan’s argument becomes particularly interesting. He believes the industry has fundamentally misunderstood memory itself. Rather than viewing memory as a database or storage mechanism, he views it as an adaptive process that continuously evolves through interaction with the environment. In this framework, memory is not simply a collection of stored facts. It is the mechanism through which understanding emerges.
That distinction may ultimately determine whether AI remains a sophisticated tool or evolves into a genuine collaborator.
Intelligence and Knowledge Are Different Things
Another theme that emerged repeatedly throughout the discussion was the distinction between intelligence and knowledge. While these concepts are often treated as interchangeable within AI conversations, they describe fundamentally different capabilities.
Knowledge refers to accumulated information. Intelligence refers to the ability to acquire, apply, and adapt that information in useful ways.
The difference becomes easier to understand through a human analogy. A person who has spent twenty years studying chess possesses an enormous amount of knowledge about the game. Another person who learns to play at a master level within a remarkably short period demonstrates a different quality altogether. The first reflects accumulated knowledge. The second reflects intelligence.
The AI industry often conflates these two dimensions.
When a model becomes larger and absorbs more training data, it undoubtedly acquires more knowledge. It gains access to more facts, more examples, and more representations of human language and behavior. Yet whether that automatically translates into proportional gains in intelligence is far less clear.
This distinction matters because it influences how we think about the future of AI architectures. If intelligence and knowledge are separate capabilities, then perhaps they should not be embedded within the same system. Perhaps reasoning and memory should be treated as distinct but complementary functions rather than compressed into a single set of model weights.
Johan argues that much of today’s architecture attempts to force both intelligence and knowledge into the same parametric space. The result is increasingly large models that become more knowledgeable but do not necessarily become proportionally more adaptive.
Interestingly, this perspective aligns with a growing body of research examining the limitations of pure scaling. While larger models continue to improve, the cost of those improvements is rising dramatically. Frontier model development now requires extraordinary investments in infrastructure, energy, specialized hardware, and training data. At the same time, many researchers have begun exploring alternative approaches that focus on architecture, memory, reasoning systems, and agentic workflows rather than scale alone.
This does not mean scaling has stopped working. Far from it. The latest generation of models continues to produce remarkable results. However, it does suggest that scale alone may not solve every problem.
At some point, intelligence may require a different kind of architecture.
Why Today’s AI Forgets
Perhaps the most provocative idea from the conversation is that many of the limitations we associate with reasoning may actually be memory problems in disguise.
When people discuss hallucinations, inconsistency, or long-term planning failures, the conversation usually focuses on model intelligence. We ask whether the system can reason well enough. We question whether it understands logic. We wonder whether it can think.
But human cognition offers a different perspective.
Many human mistakes are not failures of reasoning. They are failures of memory.
We forget important details. We lose context. We overlook relevant experiences. We fail to connect current situations with previous lessons. Our reasoning may remain intact, but our memory fails to provide the information needed to apply it effectively.
Something similar may be happening in modern AI systems.
Current models operate primarily within the boundaries of a context window. They generate outputs based on probabilities derived from training and whatever information happens to be present in that moment. They possess no persistent understanding of events, consequences, experiences, or relationships beyond what can be reconstructed during inference.
As a result, every interaction becomes an exercise in rebuilding understanding from scratch.
This challenge becomes particularly apparent in autonomous systems. Agents frequently repeat mistakes because they have no meaningful mechanism for integrating outcomes into future behavior. They may complete tasks successfully, but they often fail to develop lasting expertise. They can search for solutions repeatedly, but they struggle to create abstractions that generalize across experiences.
Johan’s critique is that the industry has mistaken storage for memory. As he explained during the conversation, “Memory is not just retrieval and indexing and keeping things in storage. Memory has a generativity.”
That concept of generativity is important because it moves memory beyond simple recall. Human memory does not merely preserve information. It creates abstractions, identifies relationships, builds associations, and generates meaning. We do not simply remember experiences; we learn from them. The lessons become part of how we interpret future events.
If AI systems are to become long-term collaborators rather than temporary assistants, they may require similar capabilities. The future of AI may therefore depend less on expanding context windows and more on building systems that can transform experience into understanding. And that shift could fundamentally change how we think about intelligence itself.
From Retrieval to Meaning
The question, then, is what a genuine memory architecture might look like. While the industry has largely converged on variations of Retrieval-Augmented Generation as the dominant solution to memory, Johan believes that approach addresses only a small part of the problem. Retrieval is certainly valuable because it provides grounding, access to current information, and connections to proprietary knowledge sources. Organizations will continue to rely on retrieval systems because factual accuracy matters, particularly in regulated industries and high-stakes decision-making environments. Yet retrieval alone does not create understanding. It simply provides access to information. The distinction may appear academic at first glance, but it becomes critically important when organizations begin deploying AI systems that must operate over longer time horizons. A retrieval system can tell an agent what happened. A memory system can help it understand why it happened, what the consequences were, and how those lessons should influence future decisions. One functions as a library. The other functions as accumulated experience.
This distinction led Johan and his team to explore concepts borrowed from neuroscience and cognitive science rather than traditional software architecture. One of the concepts that appears repeatedly throughout his work is Hebbian learning, often summarized by the phrase “neurons that fire together wire together.” While modern deep learning is dominated by gradient descent and backpropagation, Hebbian principles describe how associations strengthen over time through repeated interaction. The important insight is not necessarily the biological mechanism itself, but the broader idea that memory emerges through relationships rather than isolated storage. In other words, knowledge becomes meaningful because concepts, events, outcomes, and experiences become linked together through repeated exposure and interaction. Rather than treating memory as a collection of independent records, this perspective treats memory as a living network of associations that continuously evolves as new experiences occur.
What makes this particularly relevant for enterprise AI is that most organizational knowledge already behaves in exactly this way. Companies rarely succeed because they possess individual pieces of information. Competitive advantage emerges because they understand how information connects across products, customers, markets, operations, and decisions. The most valuable knowledge inside an organization is often not found in documentation at all. It exists in the relationships between events, in lessons learned through execution, and in the accumulated intuition developed through years of experience. When executives speak about institutional knowledge, they are rarely referring to a collection of documents. They are referring to the web of understanding that helps an organization make better decisions. Yet most AI architectures today struggle to represent that type of knowledge because they are optimized for retrieval rather than relationship building.
This is where the conversation begins to move beyond conventional RAG architectures and toward something that looks more like associative memory. Rather than retrieving individual pieces of information based on semantic similarity alone, Johan describes systems that continuously adapt the relevance and meaning of memories based on how they are used, what outcomes they produce, and how they relate to other memories over time. The goal is not simply to retrieve the most similar piece of information. The goal is to build a system capable of constructing meaning. That distinction may ultimately determine whether future AI agents remain sophisticated search systems or evolve into something closer to long-term collaborators.
Why Statefulness Changes Everything
One of the most useful ways to understand the implications of this shift is through the concept of statefulness. Most AI systems today remain fundamentally stateless. Even sophisticated agents often operate as a sequence of loosely connected interactions coordinated through orchestration layers, workflows, prompts, and retrieval systems. They may appear persistent because external systems preserve information between sessions, but the underlying intelligence itself rarely accumulates experience in a meaningful way. Every interaction is largely reconstructed from available context rather than built upon an evolving internal understanding.
Human collaboration works differently. When a colleague joins a project, they do not start from zero every morning. Their understanding accumulates over time. They remember previous meetings, failed experiments, successful initiatives, organizational politics, customer relationships, and strategic priorities. Every new interaction builds upon an expanding foundation of context. This accumulated understanding is often what separates expertise from information. An experienced executive does not necessarily possess access to more facts than a junior employee. The difference lies in their ability to interpret those facts through the lens of experience.
If AI is to become a genuine participant in knowledge work, it will likely require similar capabilities. This is why stateful AI may prove to be one of the most important developments of the coming decade. A stateful system does not merely remember information. It remembers experiences, outcomes, and relationships. It develops continuity. It can connect events that occur months apart. It can recognize patterns that emerge over time. Most importantly, it can build context rather than simply consume it.
For enterprises, the implications are substantial. Much of today’s excitement around agents focuses on automation. Organizations want systems that can complete tasks, answer questions, generate reports, write code, and coordinate workflows. Those capabilities are certainly valuable, but they represent only the first stage of the opportunity. The larger opportunity emerges when agents begin accumulating organizational understanding. Imagine a research assistant that remembers every project conducted within an organization over several years. Imagine a software engineering assistant that learns from every deployment, every bug, and every architectural decision. Imagine a strategic planning system that continuously incorporates lessons from previous initiatives, market shifts, and customer outcomes. Such systems would not merely automate work. They would accumulate institutional knowledge.
The distinction may sound subtle, but it fundamentally changes the economics of AI. Today’s systems often require repeated inference to reconstruct understanding. Tomorrow’s systems may be able to build upon what they have already learned. In a world where inference costs, energy consumption, and infrastructure investments continue to rise, that capability could become enormously valuable.
The Rise of Cognitive Capital
Perhaps the most strategic implication of Johan’s perspective is that it reframes how organizations should think about their data. For years, data has been described as the new oil. More recently, enterprises have begun treating proprietary data as the foundation of competitive AI strategies. Yet even this framing may be too narrow because it assumes the value lies primarily in the information itself.
A more useful concept may be cognitive capital.
Cognitive capital represents the accumulated understanding generated through the interaction between data, experience, decisions, and outcomes. It is the layer of organizational intelligence that emerges over time. Every customer interaction contributes to it. Every project adds to it. Every operational success strengthens it. Every failure enriches it. Yet despite its importance, most organizations are remarkably poor at preserving it.
One of Johan’s most insightful observations during the conversation concerned the role of failure in organizational learning. Companies often focus obsessively on successful outcomes because those outcomes are easier to celebrate, document, and communicate. Yet failed initiatives frequently contain far more valuable learning signals. Understanding why something did not work often provides deeper insight than understanding why something succeeded. Human experts know this intuitively. Their expertise is built not only on successes but also on accumulated mistakes. The same principle applies to AI systems. If organizations want systems capable of understanding their business, they cannot simply feed them records of successful outcomes. They must also preserve the failures, dead ends, false assumptions, and unsuccessful experiments that shaped those outcomes.
Viewed through this lens, memory becomes more than a technical capability. It becomes a strategic asset. Organizations that successfully capture, structure, and compound cognitive capital may develop significant advantages over competitors that focus solely on models and infrastructure. Foundation models will continue to improve and become increasingly accessible. Proprietary memory, however, remains inherently difficult to replicate because it reflects the unique experiences of a specific organization operating within a specific environment over time.
This perspective may also help explain why so many enterprises struggle to realize value from AI despite investing heavily in data platforms and infrastructure. Data alone does not create intelligence. Experience transformed into understanding creates intelligence. The organizations that learn how to capture that transformation may be the ones that benefit most from the next phase of AI development.
Beyond Monolithic Models
As the conversation progressed, the discussion naturally expanded beyond memory architectures and toward a much larger question: what might the path to artificial general intelligence actually look like? This is where Johan’s perspective becomes particularly interesting because it challenges one of the dominant assumptions that has guided much of the AI industry over the past decade. While most frontier AI laboratories continue to pursue increasingly large foundation models, Johan argues that true general intelligence is unlikely to emerge from a single monolithic system. His reasoning is rooted in a relatively simple observation. Intelligence, knowledge, memory, perception, reasoning, adaptation, and learning are fundamentally different capabilities, yet modern architectures attempt to compress all of them into the same set of parameters. The result is extraordinary capability, but also significant limitations that become increasingly apparent as systems encounter complex, dynamic environments.
His argument draws support from both mathematics and biology. Human intelligence is not monolithic. No individual possesses expertise across every domain. No single person understands every scientific discipline, masters every language, or solves every problem. Instead, human intelligence emerges through specialization, collaboration, and diversity of perspectives. Organizations become intelligent because individuals contribute different forms of expertise. Markets become intelligent because millions of participants process information differently. Scientific progress emerges because researchers approach problems from multiple directions simultaneously. Collective intelligence is not created through uniformity. It emerges through diversity.
This idea led Johan to propose a future in which advanced AI systems resemble ecosystems more than individual models. Rather than a single superintelligent entity containing all knowledge and capabilities, he envisions networks of specialized systems working together while maintaining distinct perspectives and distributions of information. During the conversation he referred to this concept as a form of “agentic DNA,” arguing that meaningful collective intelligence requires diversity among participating systems. If every agent is trained on the same data, follows the same reasoning pathways, and reaches the same conclusions, then adding more agents simply creates redundancy rather than intelligence. Diversity, in this view, is not a limitation. It is a prerequisite for higher-order intelligence.
Interestingly, the industry may already be moving in this direction, even if unintentionally. The rapid rise of agentic architectures, orchestration frameworks, reasoning chains, tool use, retrieval systems, planning engines, and multimodal models suggests that intelligence is increasingly becoming a property of systems rather than individual models. What organizations deploy in production today is rarely a standalone foundation model. Instead, it is a collection of components working together. Models interact with databases, search systems, APIs, workflows, memory layers, and decision engines. The intelligence emerges through coordination. As these architectures continue to evolve, it becomes increasingly plausible that future breakthroughs will occur at the system level rather than exclusively at the model level.
JEPA, World Models, and the Search for Understanding
One of the more fascinating moments in the discussion came when the conversation turned toward emerging alternatives to traditional autoregressive language models. In particular, Johan expressed interest in the growing body of work surrounding world models and Joint Embedding Predictive Architectures, often referred to as JEPA. While these architectures remain relatively early compared to today’s dominant large language models, they represent an important shift in how researchers think about intelligence itself. Rather than predicting the next token in a sequence, world models attempt to build representations of how reality works. Their objective is not merely to generate plausible language but to understand the underlying structure of the environment they are operating within.
The distinction may seem technical, but it reflects a deeper philosophical question about what intelligence actually is. Traditional language models excel at prediction. They generate highly plausible continuations of existing patterns. Their capabilities emerge from learning statistical relationships across enormous datasets. World models pursue a different objective. They attempt to learn the underlying dynamics that produce those patterns. In essence, they seek understanding rather than prediction alone.
Johan does not see these approaches as competing alternatives. Instead, he views them as complementary. In his view, future AI systems will likely require both capabilities. They will need robust world models capable of understanding the structure of reality, while simultaneously maintaining adaptive memory systems capable of incorporating new experiences as the world changes. One provides grounding. The other provides adaptation. One learns the rules of the game. The other learns how the game evolves over time. Together they may offer a glimpse of architectures capable of moving beyond many of the limitations that characterize current systems.
This perspective resonates strongly with challenges facing enterprises today. Most organizations operate in environments that are dynamic rather than static. Markets evolve. Regulations change. Customer expectations shift. Competitive landscapes transform. Knowledge that was accurate yesterday may become obsolete tomorrow. Static intelligence struggles in such environments because it relies on representations frozen at training time. Adaptive intelligence, by contrast, can continuously update its understanding as new information emerges. The ability to maintain continuity while adapting to change may become one of the defining characteristics of successful AI systems over the next decade.
Model Sovereignty and the Enterprise AI Stack
The conversation also touched on another issue that is becoming increasingly important for organizations around the world: sovereignty. While much of the public discussion surrounding AI focuses on model performance, enterprises are increasingly asking a different question. Who owns the intelligence that powers their business?
For the past several years, the answer has largely been external providers. Organizations have gained extraordinary capabilities by accessing frontier models through cloud APIs. This has dramatically accelerated adoption and lowered barriers to experimentation. Yet it has also introduced new dependencies. Costs remain unpredictable. Regulatory requirements continue to evolve. Data governance concerns persist. Strategic control becomes increasingly difficult when core capabilities depend on infrastructure controlled by external entities.
Johan summarized this challenge through a phrase he previously encountered during his work in the open-source AI community: “If it’s not your model, it’s not your mind.” While few organizations possess the resources required to train frontier-scale models from scratch, the underlying principle remains highly relevant. Enterprises may not own the foundation models, but they can own their memory. They can own their knowledge. They can own the contextual intelligence that emerges from their unique experiences, decisions, and operations.
This idea has significant strategic implications because it shifts the conversation away from competing with hyperscalers and toward developing assets that are inherently difficult to replicate. Foundation models are rapidly becoming commodities. The gap between leading models remains meaningful, but it continues to narrow. Memory, by contrast, reflects the accumulated experiences of a specific organization. It captures relationships, decisions, lessons learned, and contextual understanding that cannot easily be reproduced elsewhere. As a result, the most defensible layer of future enterprise AI may not be the model itself but the memory architecture surrounding it.
For leaders developing AI strategies, this perspective offers an important reframing. Rather than asking which model to adopt, organizations may benefit from asking how they can preserve, structure, and compound organizational knowledge. The winners of the next decade may not be those with access to the most powerful models. They may be those who build the most effective systems for accumulating cognitive capital.
The Future of Human-AI Collaboration
Perhaps the most compelling aspect of Johan’s vision is that it shifts the conversation away from replacing humans and toward augmenting them. Much of the public discourse surrounding AI remains focused on automation, productivity, and efficiency. While those outcomes are undoubtedly important, they represent only one dimension of the opportunity. The larger opportunity may lie in creating systems that help humans preserve and expand collective knowledge.
Throughout history, progress has depended on humanity’s ability to accumulate knowledge across generations. Language enabled us to share ideas. Writing enabled us to preserve them. Printing enabled us to distribute them. Digital technology enabled us to access them instantly. Each step expanded our collective intelligence by improving our ability to store and transmit information.
The next phase may involve something different. Instead of merely storing information, we may create systems capable of preserving context, relationships, experiences, and understanding. Such systems would not simply retrieve knowledge. They would help organizations build upon it. They would act less like search engines and more like institutional memory.
This possibility carries profound implications for leadership, decision-making, innovation, and organizational learning. A company that successfully compounds knowledge gains an advantage that extends beyond efficiency. It becomes capable of learning faster than competitors. It avoids repeating mistakes. It preserves expertise despite employee turnover. It creates continuity across projects, teams, and generations of leadership. In an increasingly complex and rapidly changing world, that capability may prove more valuable than any individual AI model.
Looking Beyond the Context Window
The most valuable conversations in technology are often the ones that challenge prevailing assumptions. Johan Thulin’s argument does exactly that. While the industry remains focused on model scale, benchmark performance, and ever-expanding context windows, he invites us to consider a different possibility. The next frontier may not be bigger models. It may be better memory.
That does not diminish the extraordinary achievements of modern AI. Foundation models have transformed what is possible in software, research, creativity, and knowledge work. Their progress has been remarkable and will undoubtedly continue. Yet history suggests that transformative technologies rarely evolve along a single dimension. As one bottleneck is removed, another emerges. Today, intelligence may no longer be the only constraint. Continuity, memory, adaptation, and accumulated understanding are becoming increasingly important.
Whether Johan’s specific vision proves correct remains to be seen. The future of AI is notoriously difficult to predict, and breakthroughs often arrive from unexpected directions. Yet his central thesis deserves serious consideration because it addresses a challenge that many enterprises are already encountering in practice. The systems we are building today are remarkably capable, but they remain surprisingly forgetful. They can access information, yet struggle to accumulate experience. They can answer questions, yet often fail to develop understanding.
If the next decade of AI is defined by the transition from tools to collaborators, then memory may become the most important capability of all. Not because memory replaces intelligence, but because intelligence without memory can only take us so far. The organizations that recognize this distinction early may be the ones that build not only more capable AI systems, but more resilient, adaptive, and intelligent enterprises.
*This article was enhanced with the help of AI tools, drawing on the podcast transcript and complementary online research. To go deeper into the source material, I encourage you to listen to the full episode and make your own learning.
To see or hear the entire episode, please click on this link.







