

For years, enterprise data architecture was built for a single, slow-moving consumer: the human analyst. We optimized for dashboards, SQL queries, and weekly reports. But lately, we have reached an Architectural Reckoning. The primary consumers of our data are now autonomous AI agents that operate at millisecond speeds and require “perfect context” to avoid disastrous hallucinations.
The traditional “Data Warehouse” is a static resting place in the eyes of an agent. To support Agentic AI at Scale, we are witnessing the death of passive storage and the birth of the Adaptive Context Layer. This is a world where data isn’t just stored, but it is also “engineered” in real-time to provide agents with the Minimum Viable Context (MVC) they need to act with total authority.
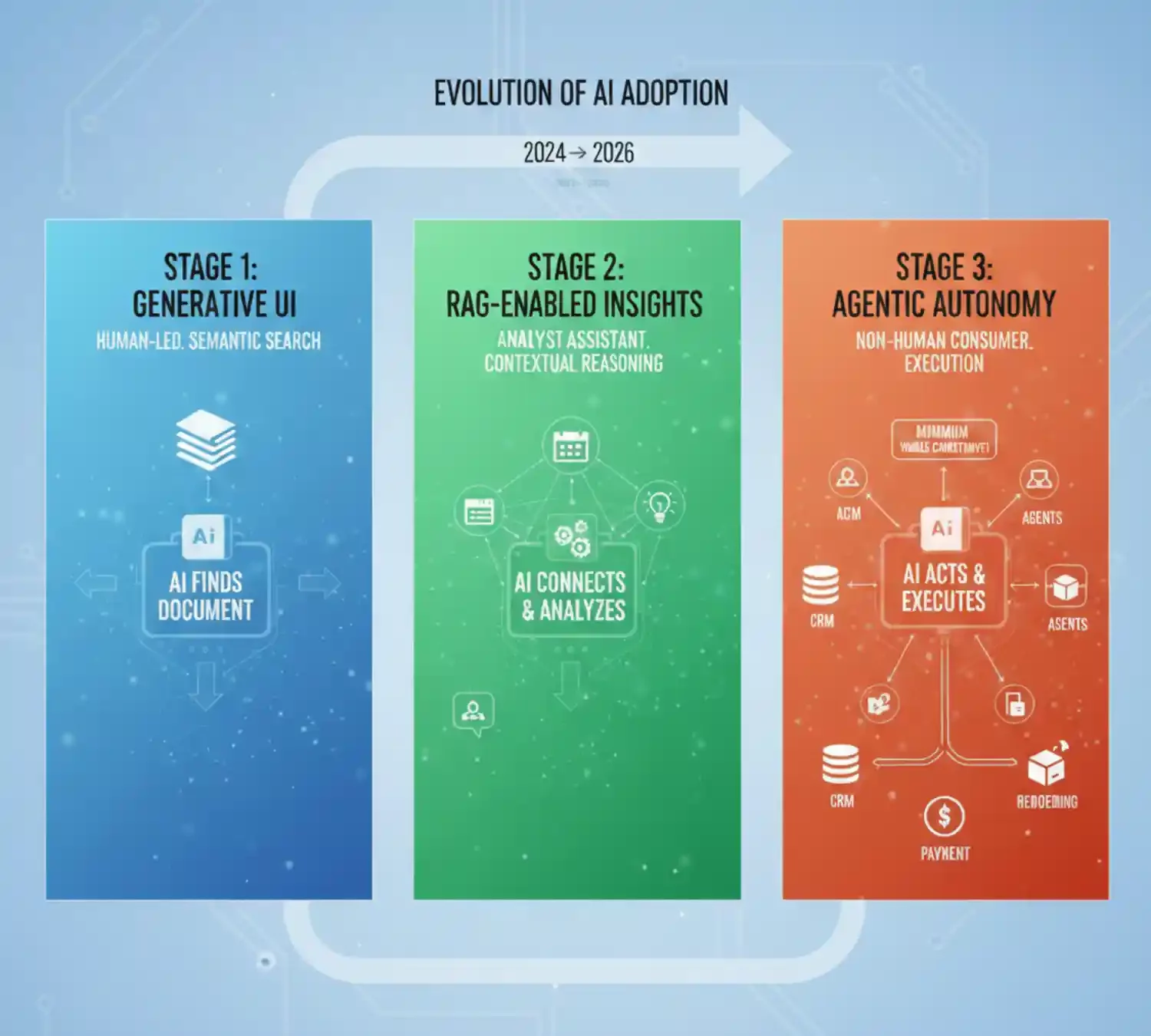
The Maturity Curve: From Assisted UI to Agentic Autonomy
But this reckoning is not merely technical; it is the ultimate test of AI Adoption. True adoption in 2026 has moved past the ‘User Interface’ phase and into the ‘Agentic Core.’ Companies are realizing that you haven’t truly adopted AI if you are still treating it like a faster search engine. Real adoption occurs when the architecture allows an agent to move from ‘suggesting’ to ‘executing’. This is a leap that is only possible once the organization trusts its Adaptive Context Layer enough to take the human analyst out of the middle of every transaction.
This transition follows a specific maturity curve that dictates how an enterprise interacts with its data.
The End of Flat RAG: The Rise of GraphRAG
Standard Vector RAG, which was the “Gold Standard” of 2024 and in that year has hit a ceiling. While vector similarity is great for finding “similar-sounding” text, it fails miserably at the complex, multi-hop reasoning required by 2026 agents.
The Problem: The “Context Clumping” Hallucination
In a flat vector store, data is flattened into chunks. If an agent asks, “Which vendor has the highest risk of delay based on our last three Q2 audits?”, a standard RAG system might pull three different audit PDFs. However, it cannot “connect the dots” between the vendor name in one PDF and the risk-score table in another. It “guesses” the connection, leading to Context Hallucinations.
The Solution: Knowledge Graph Grounding
This is why GraphRAG has become the most searched-for architecture this quarter. By structuring data into Nodes (entities) and Edges (relationships), we give the AI a “Map” rather than just a “List.”
- Relationship-Aware Retrieval: Instead of just finding similar text, GraphRAG allows an agent to “traverse” the data. It sees that Vendor A is connected to Audit B, which is flagged by Compliance Officer C.
- Multi-Hop Reasoning: 2026 agents use graphs to follow a logic chain: Symptom X → Linked to Drug Y → Interacts with Condition Z. A flat vector search would likely miss the middle link; a graph makes it a deterministic path.
- Semantic Density: By using Knowledge Graph Grounding, we reduce the “noise” sent to the LLM. We don’t send the whole PDF; we send the specific “Subgraph” that contains the factual truth.
Standardizing the Interface: The Model Context Protocol (MCP)
If GraphRAG provides the “map” for AI reasoning, MCP is the universal port that allows agents to plug into that map. In early 2026, MCP officially earned its nickname as the “USB-C for AI”. Before MCP, connecting an AI agent to an enterprise database was a nightmare of custom “glue code” and vendor-specific APIs. If you switched from one LLM provider to another, the entire integration layer would break. MCP has solved this by creating a standardized, open-source language for how models and data sources communicate.
The End of the “N x M” Integration Problem
“N x M” refers to a complexity trap where every new tool you add creates an exponential amount of work. Traditionally, if you had 5 AI models and 10 data sources, you needed 50 custom integrations. With MCP, you build one MCP Server for your data source, and any MCP-compliant agent can instantly discover and use it.
In the examples from the latest models, a developer can spin up a Postgres or Snowflake MCP server in minutes. Postgres and Snowflake stands for the Model Context Protocol, an open-source standard that allows AI agents and Large Language Models (LLMs) to securely interact with external tools and data sources, such as databases.
The AI agent doesn’t need to be “taught” how to use the database; it simply queries the server’s capabilities and starts pulling context autonomously.
Beyond Reading: The “Action” Protocol
Unlike traditional REST APIs which are often “read-only” or require manual human triggers, MCP supports Two-Way Interaction.
MCP defines “Tools,” “Resources,” and “Prompts” as universal primitives.
An agent doesn’t just read a customer’s record. It can use an MCP Tool to update a CRM, trigger a refund, or generate a new support ticket. It treats an entire enterprise stack as a single, programmable interface.
Why “Standardization” is the New Security
One of the most intriguing terms this year is “MCP Gateway Security”. By standardizing the interface, we’ve also standardized the guardrails.
Because MCP is a structured protocol, security teams can implement “Intercepting Proxies” that inspect every agent request. If an agent tries to pull data it isn’t authorized for, the MCP layer blocks the request before it even reaches the database, providing a centralized audit trail for every “non-human” interaction.
Context Engineering: Designing for the “Non-Human Consumer”
In the traditional data world, we were obsessed with “Big Data” which is the idea that more data always leads to better insights. But in the agentic world of 2026, “Big Data” is a liability. Loading an AI agent with massive, unrefined datasets doesn’t just increase costs but it also creates “Context Rot”, where the model’s attention is diluted by irrelevant noise, leading to slower reasoning and higher error rates.
This has given rise to a new architectural discipline: Context Engineering.
From “Dumping” to “Dosing”: The MVC Approach
The core principle of Context Engineering is Minimum Viable Context (MVC). Rather than pushing every potentially relevant document into the prompt, the architecture is designed to “dose” the agent with the exact amount of information required for the current step of its task.
Instead of pre-loading a massive context window, the system uses a “Pull Model”. The agent performs an initial reasoning step, identifies a specific knowledge gap, and then queries the data layer for a highly targeted “snippet” of information, making this a process of Just-in-Time Retrieval.
By serving only the MVC, enterprises are seeing a reduction in inference costs of up to 90%. Now the goal isn’t to see how much the AI can remember, but how little it needs to know to be right.
Solving the “Context Rot” Problem
Analyzing data, calling tools, and self-correcting is considered a loop. When an agent runs in this continuous loop, it generates a massive amount of internal “chatter.” Without proper engineering, this chatter fills up the context window, causing the model to lose track of the original goal.
Modern architectures now use semantic caches to store and refer to previous “thoughts” and results. This allows the agent to “forget” the messy middle steps of a calculation while “remembering” the factual conclusion, keeping the context window clean and potent.
Advanced context layers now automatically “prune” irrelevant metadata and redundant headers before they reach the model. If an agent is querying a database, it doesn’t need the full schema, but it only needs the three columns relevant to the current “intent.”
From ETL to “Just-in-Time” Context
In the UX era, we used ETL (Extract, Transform, Load) to prepare data for human dashboards. In the AX (Agent Experience) era, we use Context Orchestration.
Traditional RAG – pre-processes everything into a vector store and hopes the “top-k” results are enough.
Context Engineering – equips the agent with the tools to iteratively probe sources, reformulate its own queries, and “steer” itself toward the most relevant information.
Autonomous Governance: The Metadata Guardrails
As we empower AI agents to move from “reading” to “acting,” the old model of manual governance such as spreadsheets, periodic audits, and static permissions, has created a catastrophic bottleneck. In an agentic ecosystem, governance must be as fast and autonomous as the agents themselves. This is achieved through Metadata-Driven Guardrails: a system where the data architecture itself acts as a real-time immune system.
Policy-as-Code: The Shift from “Rules” to “Enforcement”
We no longer rely on an agent “promising” to follow a PDF of company policies. Instead, policies are written as executable code that the data layer enforces at the point of access.
Every data packet is wrapped in a metadata “envelope” that includes its classification. When an agent attempts a tool-call to access a database, the metadata guardrail automatically inspects the agent’s current task identity. If a marketing agent tries to pull raw salary data for a “budget summary” task, the data layer anonymizes or blocks the specific fields in flight, without the agent even needing to ask.
The Semantic Kill-Switch and “Contextual Fencing”
One of the most powerful architectural features of 2026 is the Semantic Kill-Switch. This is a dynamic guardrail that monitors the “reasoning health” of an agentic workflow.
If the metadata framework detects that an agent is beginning to “drift” into prohibited territory the architecture flips a switch when it encounters and attempts to access cross-border data that violates residency laws (GDPR/Data Act). Rather than crashing the system, the guardrail performs Contextual Fencing. It “prunes” the agent’s view of the data mesh, effectively blindfolding it to the sensitive sources while allowing it to continue its task using only “safe” public or synthetic data.
Automated Lineage: The “Digital Receipt” for Accountability
Transparency is the byproduct of a well-architected metadata layer. In 2026, every decision made by an agent is backed by an automated Lineage Trace.
The architecture automatically records a “Forensic Snapshot” of the data as it existed at the moment of the decision. This creates a machine-readable audit trail that links the source data, the transformation logic, and the agent’s rationale into a single, unalterable record. If a regulator asks why a specific autonomous action was taken, the platform doesn’t provide a vague guess. In other words, it provides the “Digital Receipt” in seconds.
Leading the Traceable Revolution
The evolution of the data practitioner now centers on the transition from model-centric development to the architectural oversight of agentic ecosystems. For the modern expert, this means a pivot toward robust governance frameworks, utilizing the Manager Agent Pattern and AI Nutritional Labels to standardize transparency across automated workflows. By prioritizing clear, verifiable logic over opaque automated processes, practitioners can establish “digital receipts” as the baseline for system auditability and cross-functional trust.
Moving forward, the technical objective is to engineer systems that are not only scalable but inherently self-documenting and aligned with human intent, thereby ensuring the operational integrity of the next generation of enterprise infrastructure.

