
GitHub as a platform doesn’t need an introduction. Everyone that has even been closely or remotely connected to some sort of code development, testing, production or even marketing of software products, has a very clear understanding of GitHub.
As a software development platform, GitHub opens its doors for developers all over the world to host, share, and discover software, particularly but not limited to open-source. Consequently, one is inspired to ask just how much data of code GitHub actually stores.
Clair Sullivan, Machine Learning Engineer at GitHub, came to Data Innovation Summit to enlighten us about how much code data they actually have and what exactly they do with it.

At the time of her presentation, Clair stated that GitHub stored around 0.8 petabytes of data of code produced by developers.
Going a step forward, Clair explains that all that data can be represented in a graph – of connected data. What does that mean? Simply put, the graph presents two pieces of data connected together, like a developer writing code, pulling requests, creating issue, making a comment, cloning a repository.
Duplicate code – Why it’s such a problem for GitHub
Clair’s talks focused on a particularly interesting aspect of code – duplicate code. You may wonder why copying a piece of code and posting it in another repository would cause such a fuss.
To give us an idea of why duplicate code is the focus of her talk, Clairs draws attention to a paper on duplicate code in GitHub and how much of it resides there.

As we can see, a staggering 93% of JavaScript on GitHub is duplicate. Considering the amount of duplicate code, GitHub is focused on finding a way to leverage it and help developers in their code development by suggesting existing code based on similarity.
Types of duplicate code
Clair describes that there are 5 different types of duplicate code:
- Type 0 – completely identical
- Type 1 – the only difference is in comments and whitespace
- Type 2 – can also include variations in identifier names and literal values
- Type 3 – syntactically similar with differences as the statement level (can be added, removed, or modified)
- Type 4 – syntactically different but semantically similar (they do the same thing)
Detecting Type 0, 1 and 2 is quite easy using hashing, but the real fun starts with Type 3 and 4 as they are much more complex to detect.
Clair describes that there are 5 different types of duplicate code:
- Type 0 – completely identical
- Type 1 – the only difference is in comments and whitespace
- Type 2 – can also include variations in identifier names and literal values
- Type 3 – syntactically similar with differences as the statement level (can be added, removed, or modified)
- Type 4 – syntactically different but semantically similar (they do the same thing)
Graphs of code
Explaining Type 3 duplicate code, Clair gives the example of the two functions below:


Image source: Clair Sullivan’s PDF presentation at the Data Innovation Summit 2019
The functions may look very different at first sight, but both are doing a form of addition.
ASTs or abstract syntax trees are how code is put together an in its essence it’s nothing other than graphs, which are directed and acyclic, meaning there are no loops in them.
If we represent the two above AST functions into graphs, we get these two visuals below:

Graph calculations are represented through the adjacency matrix – good news for machine learning people that want to crunch numbers. The adjacency matrices turn the graph into numbers and vectors that ML people can work with.
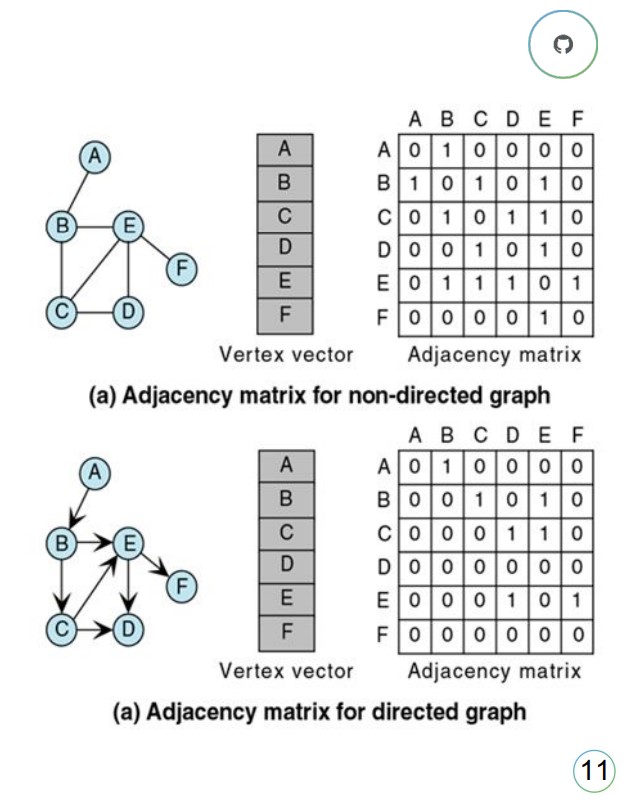
But going back to the headline of the article, it said using deep learning and for that we need images. What if we take these numbers, rows and columns and turn them into an image, Clair suggests. This is what Clair did in her research; she took the code and the graph of it and turned it into a picture of the code, the AST adjacency matrix of a function, to be more precise:

The next step was to apply a convolutional neural network to see if she can detect duplicate images, i.e. codes.

If we can identify developers going down the path of creating duplicate code, can we help them write that code?
Deep learning model for detecting duplicates in graphs of code
Clair explained how the workflow went with running deep learning on the graph images for the purpose of detecting duplicate code.
She relied on the labelled dataset called Big Clone Bench which contains 6.7 million Java files labelled for their type of duplicates. The idea was to go through all of them and pick the Type 3 duplicates, which are the same language, syntactically slightly different, but semantically identical.
First, she identified two files in the Big Clone Bench dataset which are labelled as Type 3 duplicates and compared them. Then she created a training set based on those labels of either Type 3 or not Type 3 leaving them with Type 3 clone or a negative clone which they used in the training.
Then, the code is converted into ASTs JSON, which is converted into an adjacency matrix and a convolutional neural network code is written to define if they are Type 3 duplicates or negative duplicates. The process for detecting duplicates is done at a file and function level.

Results
After running the test on file to file comparison, Clair got an accuracy on the test set of almost 93%. The training was done on 5000 negative clones and 8220 Type 3 clones, with 20% loss.

As for the function to function comparison, she got 97.7% accuracy on a test done with nearly 28.000 negative clones and 53.000 total training cases, which are great numbers.
In order to make sure she wasn’t being fooled by the results, as it doesn’t happen rarely in deep learning algorithms, Clair added random noise to the images by 1%. As a result, the test accuracy went down, as expected, but as she states, there is no 100% proof that results are accurate and have to be taken with a grain of salt.
But at the end of the day, Clair presented only one way, one node in the whole graph, for doing graph analytics on code.
Future work
Clair admits that GitHub’s current approach for clone detection using O(n2) is not efficient and that’s why it’s not in production. As she says, GitHub is working on finding a way out of this O(n2) modality.
However, they focus the majority of their efforts on detecting Type 4 duplicates, which as Clair states “is the Holy Grail” for research. For detecting Type 3 they worked with Java, but they want to expand to comparing Java to Haskell.
But code is not the only data on GitHub as we’ve seen. There’s data on the users, their activity and interactions on the site and all of it can potentially be represented as a graph, Clair points out. These are some of GitHub’s exciting area of work that hopefully we’ll soon see results of.











Add comment